Les Transformers remplacent-ils les CNN en détection d'objets ?
Au cours de la dernière décennie, les CNN ont déclenché une nouvelle révolution en vision par ordinateur. En 2020, les ViT ont attiré beaucoup d'attention. Les Transformers remplacent-ils les CNN ?
Picsellia Team
·13 min read
Pret a construire de la vision par ordinateur ?
Des images brutes aux modeles en production. Essai gratuit, sans carte bancaire, resiliable a tout moment.
Au cours de la dernière décennie, les CNN ont déclenché une révolution en vision par ordinateur. Le deep learning a remporté la première place dans de nombreux concours de vision par ordinateur, et de nombreuses techniques traditionnelles de vision par ordinateur sont devenues obsolètes. En 2020, une nouvelle architecture, le Vision Transformer (ViT), a attiré beaucoup d'attention dans la recherche. Elle a montré des résultats prometteurs en surpassant les CNN état de l'art dans de nombreuses tâches de reconnaissance d'images, avant de les battre dans des tâches plus avancées comme la détection d'objets et la segmentation.
Les CNN deviennent-ils obsolètes avec l'invention des Vision Transformers ?
Premièrement, nous présenterons l'architecture Vision Transformer. Deuxièmement, nous expliquerons quelques différences essentielles entre les CNN et les ViT. Ensuite, nous plongerons dans une comparaison quantitative des deux architectures en termes de performance, de données d'entraînement et de temps.
En résumé
- Les CNN sont une architecture plus mature, il est donc plus facile de les étudier, de les implémenter et de les entraîner par rapport aux Transformers.
- Les CNN utilisent la convolution, une opération « locale » limitée à un petit voisinage d'une image. Les Vision Transformers utilisent l'auto-attention, une opération « globale », puisqu'elle tire des informations de l'ensemble de l'image. Cela permet au ViT de capturer efficacement les relations sémantiques distantes dans une image.
- Les Transformers ont atteint des métriques plus élevées dans de nombreuses tâches de vision, obtenant une place état de l'art.
- Les Transformers nécessitent plus de données d'entraînement pour obtenir des résultats similaires ou surpasser les CNN.
- Les Transformers peuvent nécessiter plus de ressources GPU pour être entraînés.
Transformers et auto-attention
Initialement conçus pour les tâches de traitement du langage naturel, les Transformers sont des architectures très efficaces pour les données qui peuvent être modélisées comme une séquence (par exemple, une phrase est une séquence de mots). Ils résolvent de nombreux problèmes auxquels d'autres modèles séquentiels comme les réseaux de neurones récurrents sont confrontés. Les Transformers sont composés d'empilements de blocs Transformer. Ces blocs sont des réseaux multicouches comprenant des couches linéaires simples, des réseaux feedforward et des couches d'auto-attention, l'innovation clé des Transformers, représentée par la boîte « Multi-Head Attention » dans l'image ci-dessous.
 Are transformers replacing cnns in object detection
Schéma d'un bloc Transformer. Norm désigne une couche de normalisation, Multi-Head Attention est la couche d'auto-attention, MLP est une couche entièrement connectée. Les signes plus représentent une opération (par ex. concaténation) d'une sortie avec une connexion résiduelle. Source : [2]
Are transformers replacing cnns in object detection
Schéma d'un bloc Transformer. Norm désigne une couche de normalisation, Multi-Head Attention est la couche d'auto-attention, MLP est une couche entièrement connectée. Les signes plus représentent une opération (par ex. concaténation) d'une sortie avec une connexion résiduelle. Source : [2]
Auto-attention : aperçu technique
L'auto-attention permet à un réseau d'extraire et d'utiliser des informations de contextes arbitrairement larges de manière directe. Au cœur d'une approche basée sur l'attention se trouve la comparaison d'un élément d'intérêt avec une collection d'autres éléments de la séquence pour révéler leur pertinence dans le contexte actuel. La couche d'auto-attention projette une entrée (x1, x2,..., xn) en une sortie (y1, y2,..., yn). Par exemple, la sortie y3 de la couche d'attention est une combinaison d'un ensemble de comparaisons entre x1, x2 et x3 avec x3 lui-même. L'image ci-dessous aide à éclairer cela. Notez que seuls les éléments passés de la séquence sont utilisés, c'est-à-dire que x4 n'est pas utilisé pour calculer y3.
 Are transformers replacing cnns in object detection
Projection d'une séquence d'entrée x→ vers une séquence de sortie y→ par auto-attention. Toutes les entrées précédentes xi≤j incluant celle en cours d'examen sont utilisées pour produire une sortie yj. Source : [Dan. Jurafksy, James H. Martin : Speech and Language Processing (3rd ed. draft)]
Are transformers replacing cnns in object detection
Projection d'une séquence d'entrée x→ vers une séquence de sortie y→ par auto-attention. Toutes les entrées précédentes xi≤j incluant celle en cours d'examen sont utilisées pour produire une sortie yj. Source : [Dan. Jurafksy, James H. Martin : Speech and Language Processing (3rd ed. draft)]
En interne dans la couche d'attention, une projection de l'entrée x vers un autre espace a lieu. Trois nouvelles variables latentes, q, k et v, sont créées en multipliant la variable initiale xi par des matrices apprenables WQ, WK, WV ou simplement Q, K et V. À partir de chaque entrée xi, 3 nouvelles variables qi, ki, vi sont créées. Formellement :** qi =WQxi , ki=WKxi , vi=WVxi.**
Par conséquent, un score d'attention αi est calculé, qui signale le degré de corrélation/signification existant entre deux entrées xi, xj. Plus leur corrélation dans le contexte de la séquence est forte, plus le score d'attention est élevé.
 Are transformers replacing cnns in object detection
Are transformers replacing cnns in object detection
Enfin, la sortie de la couche d'attention yi est calculée comme la somme pondérée :
 Are transformers replacing cnns in object detection
Are transformers replacing cnns in object detection
Dans une couche Multi-Head attention, nous avons plusieurs couches d'attention de ce type. Le concept est que nous pouvons détecter différentes corrélations sémantiques entre les entrées en utilisant plusieurs tableaux Qi, Ki, Vi (têtes) au lieu d'un seul. Par exemple, une tête peut détecter les pertinences géométriques tandis qu'une autre détecte les pertinences de texture. Ainsi, nous pouvons mieux interpréter les dépendances présentes dans une séquence.
Transformer les images en données séquentielles
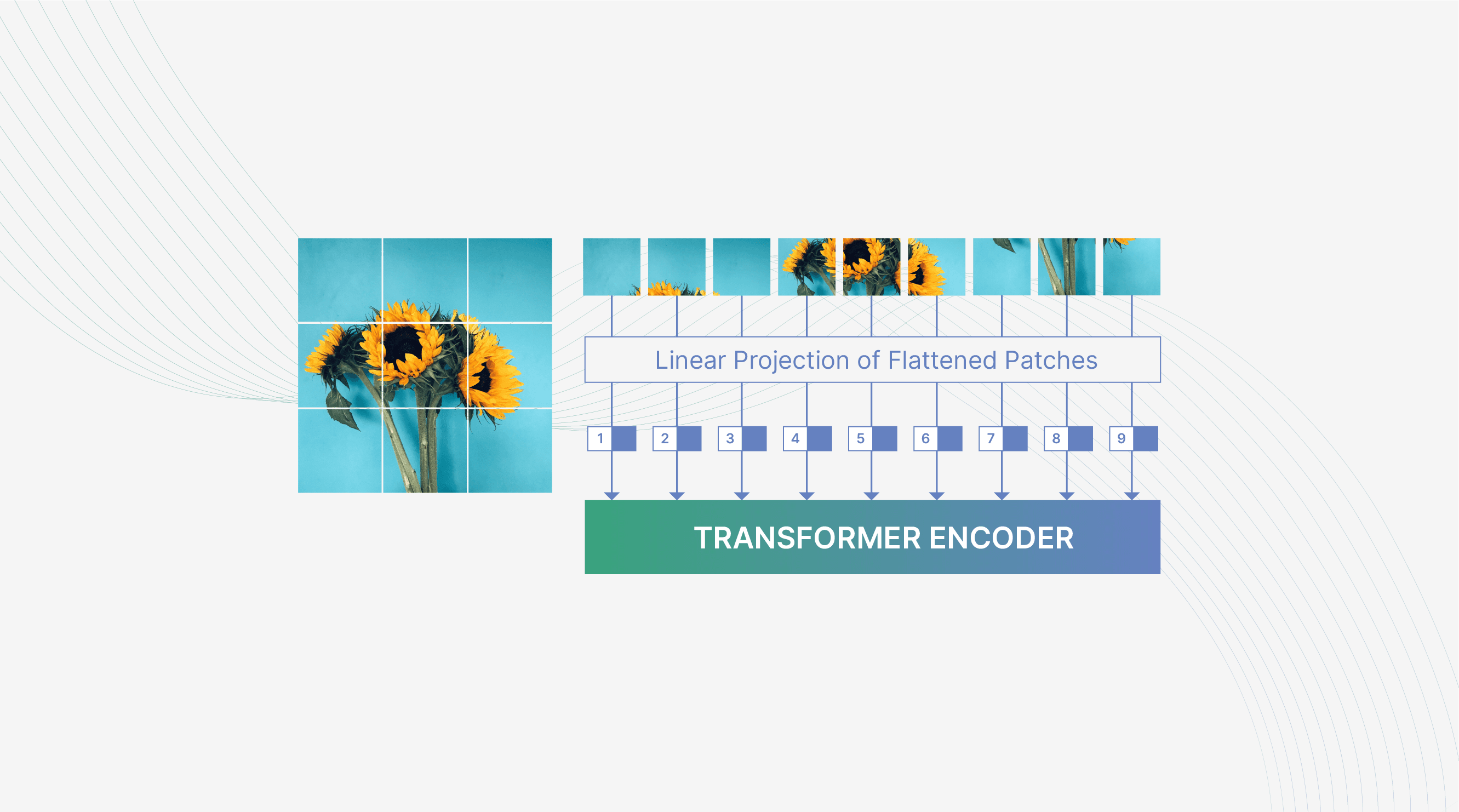
Tout ce que nous avons expliqué concerne les données séquentielles, mais les images sont représentées comme des matrices 3D, pas comme des séquences 1D. C'est là que réside la différence entre un Transformer NLP traditionnel et un Vision Transformer. Tout repose sur l'ingénierie d'une image pour la représenter comme une séquence. La procédure est la suivante :
- Diviser l'image originale H x W x C en patches 3D de dimensions P x P x C (P=16 a été utilisé dans [2]).
- Aplatir les patches 3D en vecteurs 1D de P2 x C éléments chacun. Une projection linéaire dans un autre espace est souvent utilisée pour créer une entrée ressemblant à un embedding textuel.
- Concaténer le vecteur aplati avec une valeur appelée embedding positionnel. Cet embedding positionnel aide à garder la trace de l'ordre spatial des patches dans l'image originale.
 Are transformers replacing cnns in object detection 63036fbd9f02db34e1a226c8 imagen 20baja
D'une image structurée à des données séquentielles. L'image est divisée en patches, les patches sont aplatis et projetés dans un autre espace. Enfin, un embedding positionnel est concaténé pour garder la trace de l'ordre spatial, avant de fournir l'entrée au Transformer. Modifié d'après [2].
Are transformers replacing cnns in object detection 63036fbd9f02db34e1a226c8 imagen 20baja
D'une image structurée à des données séquentielles. L'image est divisée en patches, les patches sont aplatis et projetés dans un autre espace. Enfin, un embedding positionnel est concaténé pour garder la trace de l'ordre spatial, avant de fournir l'entrée au Transformer. Modifié d'après [2].
Après avoir complété les étapes mentionnées ci-dessus, l'image originale de dimensions H x W x C a été transformée en N vecteurs, où N = (H x W) / P2 et chaque vecteur a P2C éléments. Maintenant, ces vecteurs peuvent être fournis au bloc Transformer, et le mécanisme d'attention découvrira les connexions entre les différents patches en calculant leurs scores d'attention. Si des patches spatialement éloignés sont sémantiquement connectés, leur score d'attention sera élevé, permettant au Transformer d'extraire des caractéristiques « globales » au lieu de simplement « locales ». Par exemple, un patch en haut de l'image et un en bas pourraient avoir une corrélation sémantique visuelle, obtenant un score d'attention élevé.
Comment et pourquoi les ViT diffèrent-ils des CNN ?
Avant de plonger plus profondément dans notre comparaison CNN vs. ViT, nous devrions d'abord discuter de quelques différences qualitatives significatives entre les deux architectures. Contrairement aux Vision Transformers, les réseaux de neurones convolutifs (CNN) traitent les images comme des tableaux de pixels structurés et les traitent avec des convolutions, l'opération de deep learning de facto pour la vision par ordinateur. À travers ces filtres convolutifs entraînables, les CNN créent des cartes de caractéristiques qui sont des représentations cachées de l'image originale, généralement inexplicables pour nous. Ces cartes de caractéristiques sont créées par l'opération de convolution qui n'affecte qu'un petit voisinage (patch) de l'image à la fois. Nous pouvons donc la considérer comme une opération locale par rapport au mécanisme d'attention du Transformer.
Bien que le paradigme de convolution ait fourni d'excellents résultats au cours de la dernière décennie, il s'accompagne de certains défis que les Transformers visent à résoudre.
- Tous les pixels ne sont pas aussi importants : les convolutions appliquent les mêmes filtres sur tous les pixels d'une image, quelle que soit leur importance. Cependant, les pixels de premier plan sont généralement plus importants que les pixels d'arrière-plan dans les tâches de vision comme la détection d'objets ou la reconnaissance d'images.
- Tous les concepts ne sont pas partagés entre les images : chaque filtre convolutif « reconnaît » des concepts spécifiques (par ex. bords, yeux humains, formes). Toutes les images auront des bords, donc un « filtre de bords » ou un « filtre de formes » sera toujours utile. Néanmoins, cela n'est pas valable pour un filtre qui détecte des caractéristiques humaines comme les yeux, car toute image sans humain rendrait le filtre inutile.
- La convolution peine à relier des concepts spatialement distants : chaque filtre convolutif est limité à opérer sur un petit voisinage de pixels. Relier des concepts spatialement éloignés est souvent vital, mais les CNN peinent à le faire. Augmenter la taille du noyau (filtre) ou ajouter plus de profondeur au CNN atténue le problème, mais ajoute de la complexité au modèle et aux calculs sans résoudre explicitement le problème.
Les Vision Transformers offrent un nouveau paradigme prometteur qui ne souffre pas de ces problèmes grâce à son mécanisme d'auto-attention qui opère à une échelle « globale ». Le mécanisme d'attention peut connecter sémantiquement des régions d'image éloignées les unes des autres, offrant une perception avancée de l'image. De plus, de faibles scores d'attention sont calculés pour les pixels sans importance, montrant des représentations plus efficaces.
Concernant l'entraînement des Transformers, plus encore que pour les CNN, le pré-entraînement auto-supervisé est utilisé sur de vastes datasets, et les connaissances sont ensuite transférées à la tâche finale en aval. L'auto-supervision et les Transformers sont une combinaison très bien adaptée. Les CNN peuvent aussi être pré-entraînés avec l'auto-supervision, mais cette méthode d'apprentissage a principalement gagné du terrain avec les Transformers qui étaient entraînés sur d'énormes datasets de texte non structuré, puis plus tard avec les Vision Transformers pré-entraînés sur de grands datasets d'images.
Comparaison A : Performance
Sur la tâche de détection d'objets (tâche COCO 2017), DEtection TRansformer (DETR) [4] et sa variation, le Deformable DETR [4], sont des architectures populaires. Dans [4], les auteurs comparent le DETR avec des références compétitives en détection d'objets comme Faster RCNN et EfficientDet [7], qui reposent tous deux sur des CNN.
Les résultats montrent que la détection d'objets avec des Transformers peut offrir une détection améliorée par rapport aux architectures Faster-RCNN lorsqu'on utilise les mêmes backbones (ResNet 50, ResNet 101) pour l'extraction de caractéristiques. En particulier, ils atteignent jusqu'à 4,7 points d'AP supplémentaires. Cependant, les détecteurs d'objets état de l'art basés sur CNN comme l'EfficientDet-D7 restent supérieurs, surpassant les Transformers sur l'AP de 3,5 points sur la tâche de vision COCO 2017.
 Are transformers replacing cnns in object detection
Tableau modifié d'après [4].
Are transformers replacing cnns in object detection
Tableau modifié d'après [4].
Une autre étude [5] a proposé le Swin Transformer comme modèle backbone pour la détection d'objets. Ils ont comparé Swin avec d'autres modèles backbone CNN état de l'art comme ResNeXt (X101) sur les tâches de détection d'objets et de segmentation d'images. Ils ont constaté que pour des réseaux avec un nombre similaire de paramètres, un backbone Transformer atteint jusqu'à 3,9 points d'AP75 supplémentaires en détection d'objets et jusqu'à 3,5 points d'AP75 supplémentaires en segmentation, faisant du Transformer un meilleur choix en termes de performance.
 Are transformers replacing cnns in object detection
APbox fait référence aux performances de détection d'objets, tandis qu'APmask à la segmentation d'images. Comparaison de différents modèles backbone pour la détection d'objets et la segmentation d'images. R50 est ResNet-50, X101 est ResNeXt-101, Swin T/S/B sont respectivement les architectures tiny, small et big du Swin Transformer. Source [5]
Are transformers replacing cnns in object detection
APbox fait référence aux performances de détection d'objets, tandis qu'APmask à la segmentation d'images. Comparaison de différents modèles backbone pour la détection d'objets et la segmentation d'images. R50 est ResNet-50, X101 est ResNeXt-101, Swin T/S/B sont respectivement les architectures tiny, small et big du Swin Transformer. Source [5]
Comparaison B : temps d'entraînement et données
Dans [2], les auteurs ont comparé les CNN état de l'art et leur architecture Vision Transformer nouvellement inventée. Le graphique ci-dessous compare la précision de classification sur ImageNet par rapport aux exemples de pré-entraînement utilisés. Une conclusion significative ressort de ces résultats. Les architectures Transformer nécessitent plus de données d'entraînement pour atteindre une précision égale ou supérieure à celle des CNN.
Initialement, seulement 10M d'images ont été utilisées pour le pré-entraînement auto-supervisé à partir du dataset d'images interne de Google, JFT. Même les grandes architectures Transformer ne peuvent pas égaler les performances de ResNet50, qui a beaucoup moins de paramètres, lorsqu'on utilise 10M d'images. Le plus grand Transformer n'égale les performances du CNN ResNet152 qu'une fois 100M d'images utilisées pour le pré-entraînement !
Ces résultats montrent que les Transformers sont assez gourmands en données, et les CNN offriront une meilleure précision lorsque les données sont rares.
 Are transformers replacing cnns in object detection
Nombre d'échantillons de pré-entraînement utilisés pendant le pré-entraînement auto-supervisé vs. la précision finale sur la tâche en aval. Les Transformers sont plus gourmands en données par rapport aux CNN. Source [2].
Are transformers replacing cnns in object detection
Nombre d'échantillons de pré-entraînement utilisés pendant le pré-entraînement auto-supervisé vs. la précision finale sur la tâche en aval. Les Transformers sont plus gourmands en données par rapport aux CNN. Source [2].
De plus, les auteurs dans [4] ont comparé le temps d'entraînement en heures GPU requis pour le challenge COCO 2017. L'entraînement d'un modèle Faster-RCNN avec 42M de paramètres a nécessité 380 heures GPU, tandis qu'un modèle DETR équivalent avec 41M de paramètres a nécessité 2000 heures GPU ! Cependant, grâce à des techniques d'entraînement améliorées et des modifications de l'architecture (Deformable DETR [4]), ils ont réussi à réduire le temps à seulement 325 heures GPU, ce qui montre que même si les Transformers nécessitent beaucoup plus de temps d'entraînement en moyenne, la recherche dans le domaine apporte certainement d'énormes améliorations !
Conclusion
Bien qu'étant des architectures relativement nouvelles, les Vision Transformers ont montré des résultats prometteurs. Ils ont suscité un énorme intérêt de recherche, donc nous ne pouvons qu'attendre des améliorations. Les ViT peuvent atteindre de nouveaux résultats état de l'art dans la plupart des tâches de vision actuellement, surpassant les CNN. De plus, une excellente étude sur les propriétés des ViT [6] a montré que par rapport aux CNN, ils sont plus robustes face aux occlusions d'objets, aux perturbations d'images et aux changements de domaine. Même après avoir mélangé aléatoirement les patches d'images, les ViT peuvent conserver leurs niveaux de précision de manière impressionnante.
Il ne fait aucun doute que les ViT sont d'excellentes architectures avec un énorme potentiel pour l'avenir de la vision par ordinateur. Cependant, leur grande faim de données pose un défi majeur pour le projet moyen de vision par ordinateur. Puisque les Transformers nécessitent 30M à 100M d'images pour le pré-entraînement auto-supervisé, il est presque impossible d'en entraîner un à partir de zéro à moins d'avoir les ressources nécessaires. Si des modèles pré-entraînés sont disponibles, le fine-tuning sur votre dataset est plus facile, mais beaucoup de données sont tout de même attendues.
Concernant le temps d'entraînement, les architectures Transformer nécessitent en moyenne beaucoup plus de ressources computationnelles. Cependant, la recherche dans le domaine a déjà offert des architectures améliorées qui nécessitent des temps d'entraînement similaires aux CNN.
D'un autre côté, les CNN peuvent toujours atteindre des performances comparables avec moins de données. Ce trait les rend toujours pertinents pour la plupart des projets de vision par ordinateur. Les CNN restent un excellent choix et résoudront probablement la plupart des tâches assez bien. De plus, les CNN sont plus matures, ce qui les rend plus faciles à construire et à entraîner. Proclamer que les CNN sont déjà obsolètes serait naïf. Nous devrions être reconnaissants d'avoir un autre excellent outil, le ViT, dans notre boîte à outils d'architectures de vision par ordinateur. Mais puisque tous les problèmes ne sont pas des clous, vous ne devriez pas toujours utiliser un marteau.
Références
[1] Visual Transformers: Token-based Image Representation and Processing for
[2] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE.
[3] Transformers in Vision: A Survey
[4] End to End Object Detection with Transformers
[5] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Suggestions Picsellia
Entrainez vos modeles a votre facon
Utilisez des pipelines pre-configures pour YOLO, SAM2 et plus encore — ou apportez votre propre code avec PyTorch, TensorFlow ou Hugging Face.
Explorer le laboratoire IALivrez de l'IA visuelle 10x plus vite
Picsellia est la plateforme MLOps de bout en bout pour la vision par ordinateur — de la gestion des donnees au deploiement en production.
Voir la plateformeRestez informe
Recevez les derniers articles sur la vision par ordinateur, le MLOps et l'IA directement dans votre boite mail.
Articles associes

De la vision par ordinateur à l'Industrie 4.0 : comment Scortex façonne l'inspection visuelle automatisée
Découvrez comment Scortex exploite l'IA et la vision par ordinateur pour l'inspection visuelle automatisée, de la détection de défauts à la détection d'anomalies et aux informations en temps réel.

Maîtriser l'annotation de données pour les projets d'IA en 2025
Cet article aborde l'importance de l'annotation de données en IA ainsi que les bonnes pratiques et stratégies pour surmonter les obstacles du labelling.

Tendances 2025 en vision par ordinateur : à quoi s'attendre
Découvrez les tendances à venir en vision par ordinateur pour 2025.