How to Reduce Training Data with Self-Supervised Learning
Self-Supervised Learning (SSL) aims to leverage large unlabeled datasets to train capable feature extractors such as CNN or ViT encoders. But what is SSL?
Picsellia Team
·9 min read
Organize your visual data today
Version datasets, manage annotations, and track lineage from one place.
Introduction and Motivation
Deep Neural Networks such as Deep CNNs are excellent feature extractors. That's why they have gained a top spot in many visual tasks. Visual Transformers (ViT) are pushing the limits even further. However, their success is largely attributed to Supervised Learning and the immense amount of training data from datasets like ImageNet, Places, Kinetics, etc.
However, collection and annotation of large-scale Image/Video datasets are very time-consuming and quite expensive, not to mention that there is not often enough unlabelled material to annotate (e.g., Medical Imaging). As a reference, the Places dataset consists of 2.5 million labeled images, ImageNet 1.3 million. At the same time, Kinetics is a labeled video dataset comprising around 500K videos, each with a duration of about 10 seconds.
With this motivation, Self-Supervised Learning (SSL) aims to leverage large **unlabeled datasets **to train capable feature extractors such as CNN or ViT encoders. Those are later used with smaller labeled datasets to train networks on a task of choice, using fewer data. Self-supervised learning derives from unsupervised learning. It aims at learning rich representations and semantically meaningful features from unlabeled data. In other words, SSL is a learning method in which you can train Networks with **automatically generated labels **produced from unlabeled datasets.
What is Self-Supervised Learning?
Simply put, Self-Supervised Learning refers to learning methods in Machine Learning that make use of automatically generated labels that originate from large unlabelled datasets. It offers very good performance without the need for large labelled datasets.
Key Concepts in Self-Supervised Learning
Before we explain how Self-Supervised Learning (SSL) works and how you can leverage it to reduce the training data, it's best to explain some key concepts.
-
Human-annotated labels are labels of data that human annotators manually create. These are the typical labels used in classic Supervised Learning.
-
**Pseudo-labels **refer to automatically generated labels that data scientists use to train the feature extraction network, commonly called "Encoder," on some pretext task. For example, we could randomly rotate images by 0°, 90°, 180°, or 270° and assign the labels 0,1,2,3, respectively, depending on the rotation. It's possible to create these labels without any human assistance!
-
**Pretext tasks **are pre-designed tasks that act as an essential strategy to learn data representations using pseudo-labels. Its goal is to help the model discover critical visual features of the data. Common pretext tasks include geometrical/color transformations and context-based tasks such as solving jigsaw puzzles. For example, a pretext task could be classifying an augmented image either as rotated by 0°, 90°, 180°, or 270°.
-
Downstream tasks are application-specific tasks that utilize the knowledge learned during the pretext task. They are chosen by the developer depending on the application's end goal. Examples include classification, object detection, semantic segmentation, and action recognition.
The Self-Supervised Framework
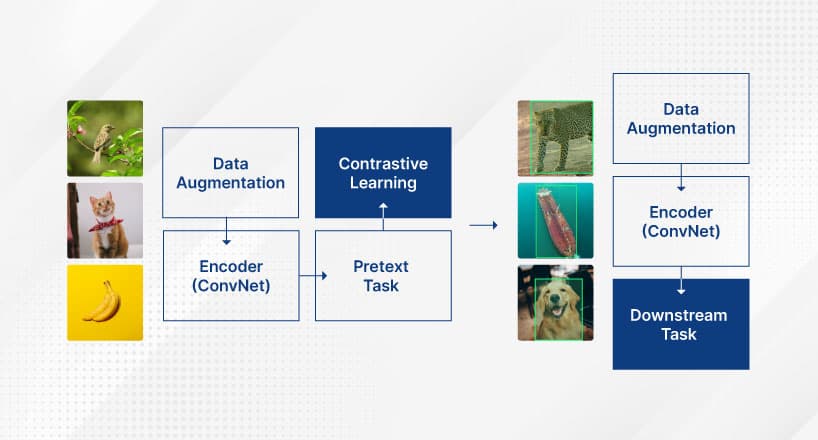
Now that we have introduced the core concepts, let's combine them to understand the Self-Supervised Learning workflow. Figure 1 offers a visual illustration. Very briefly, SSL aims at transforming an unsupervised task into a supervised task (pretext task) through automatically generated labels (pseudo-labels). Then it transfers the knowledge acquired from the pretext task to solve the final task (downstream task).
 Reduce training data with self supervised learning
Fig. 1: Self-Supervised Learning workflow. Source [3]
Reduce training data with self supervised learning
Fig. 1: Self-Supervised Learning workflow. Source [3]
Assume an Encoder model (CNN, ViT) has already been designed. Also, let's assume that we have a large image dataset at our disposal, with only a small percentage of it annotated. We begin by choosing a pretext task, such as recreating occluded parts, solving a Jigsaw puzzle, and rotation classification. Once we pick a pretext task, data augmentation takes place. This data augmentation serves a different purpose than supervised learning tasks. Here, augmentation aims to map an image into different views via stochastic transformations to create the pretext task. For example, for the pretext task of image recreation (inpainting), augmentation will randomly mask other parts of the image, and the Encoder aims to recreate these occluded parts. Pseudo-labels are created through this augmentation automatically.
 Reduce training data with self supervised learning
Fig. 2: Common pretext tasks. Source [4]
Reduce training data with self supervised learning
Fig. 2: Common pretext tasks. Source [4]
This data augmentation process encourages the network to learn hidden representations through solving the pretext task. Augmentations of the same input have more similar latent representations compared to other inputs, helping the Encoder discover the dominant features.
Moving on, the Encoder is trained on the pretext task, which is usually quite different from the downstream task. If the Encoder successfully solves the pretext task, it must have learned to extract the essential features from the images and avoid paying much attention to the noise. Otherwise, it wouldn't be able to solve these complicated tasks. However, the complexity of the data augmentation, or pretext task, must challenge the model. Otherwise, if the model solves the task very quickly, it might not have been learned, and the complexity may be low.
Once the Encoder successfully solves the pretext task with sufficient accuracy, its parameters are used as an initialization for the network that aims to solve the downstream task. Adding more layers on top of the encoder part is not unusual, which are trained solely using supervised learning. During the downstream task training, the labeled portion of the dataset is used. Hence, the network now relies on traditional supervised training to solve the final task.
Essentially, we transfer the knowledge acquired during the pretext task training down to the downstream task, similar to the well-known Transfer Learning technique but with some important differences.
How To Reduce Training Data Via Self-Supervision
In figure 3, source [5], we observe a graph depicting the test-set accuracy on the CIFAR-10 dataset vs. the number of training examples used. The plot compares a traditional supervised training method against a self-supervised method that uses rotation classification as the pretext task. The comparison begins from as low as 20 training examples and moves up to 5000 training examples. It is clear that for a low number of training examples, e.g., fewer than 1000, Self-Supervised Learning significantly outperforms Supervised learning. The lower the number of training data, the bigger the gain is. However, around 2000 training examples, we see a crossover; afterward, supervised learning achieves superior performance. These numbers are a rough guideline and will vary depending on the application. Still, the general rule of thumb is that SSL will outperform Supervised Learning by a large margin when training data is scarce.
 Reduce training data with self supervised learning
*Fig.3: The impact of training examples on accuracy for Supervised and Self-Supervised Learning. The X axis is in Log scale. Graph inspired by Source [5] *
Reduce training data with self supervised learning
*Fig.3: The impact of training examples on accuracy for Supervised and Self-Supervised Learning. The X axis is in Log scale. Graph inspired by Source [5] *
Let's recreate a similar real-world case study. You, as an ML engineer, have been asked to create a semantic segmentation computer vision model to identify certain microorganisms in microscopy images. The scientists have provided you with 3000 images of unlabeled data. You explain that to solve the problem efficiently, you need annotated data. They argue that this is a quite time-consuming and expensive activity, since domain experts must spend time on the task. They suggest that annotating 500 images will require around one month.
So, to speed up the deployment of the model, you accept to move on with 500 images at first. You suspect that 500 images will not be enough for supervised training. You try it, and indeed, the model achieved a low performance with visible signs of overfitting that are not solved with regularization methods. Then, you search for pre-trained models on a similar dataset but fail to find something relatable to the architectures that you plan to test, so Transfer Learning is not a good option. This way, everything naturally leads to Self-Supervised Learning. Now, you can leverage the 500 annotated images (except the test set, of course)** and the remaining 2500 unlabeled images. **
Not only can you design a more accurate model with much less training data, but you can later deploy this model as an annotation assistant to the scientists to speed up the labeling process of the remaining images. If your annotated dataset becomes quite large, at some point, you can retrain the model with Supervised Learning to further increase accuracy. Feedback loops will also provide another means of increasing accuracy even more.
Self-Supervised Learning (SSL) vs. Transfer Learning (TL)
Both techniques rely on knowledge transfer through parameter initialization and are excellent ways to reduce the amount of training data needed. However, they also share some significant differences.
- Transfer Learning relies on a supervised learning framework during both the pre-training and the training phase, while SSL does not use supervised learning during pre-training.
- You can't use TL on the same dataset since it wouldn't make sense. On the other hand, using SSL on the same dataset can significantly improve performance (test set must be set apart!).
Depending on the use case, you may want to pick one over the other. To help you decide which one is best, some research insights are:
- When the domain difference between the source and target tasks is large, SSL outperforms TL. For instance, using ImageNet initialization TL for medical imaging is not a good option.
- SSL is less sensitive to domain differences between the source and the target task than TL.
- Given a source task, SSL usually outperforms TL when the pre-training data is too scarce.
- If the class imbalance is prevalent in a dataset, we recommend SSL since it is more robust against imbalances than TL.
**References **
[1] Yahui Liu, Enver Sangineto, Wei Bi, Nicu Sebe, Bruno Lepri, Marco De Nadai. Efficient Training of Visual Transformers with Small Datasets
[2] Longlong Jing and Yingli Tian, Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey.
[3] Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, Fillia Makedon. A SURVEY ON CONTRASTIVE SELF-SUPERVISED LEARNING.
[4] Saleh Albewi, Survey on Self-Supervised Learning: Auxiliary Pretext Tasks and Contrastive Learning Methods in Imaging.
[5] Spyros Gidaris, Praveer Singh, Nikos Komodakis, UNSUPERVISED REPRESENTATION LEARNING BY PREDICTING IMAGE ROTATIONS.
Related from Picsellia
Organize and version your datasets
Version, slice, and manage datasets with full traceability — from raw images to production-ready splits.
Explore Dataset ManagementTrain models your way
Use pre-built pipelines for YOLO, SAM2, and more — or bring your own code with PyTorch, TensorFlow, or Hugging Face.
Explore the AI LaboratoryStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles

Computer Vision Dataset Slicing
Discover dataset slicing, a technique used to divide large datasets into smaller parts to train and test models and improve model accuracy.
Best object detection datasets in 2024
Looking to train your object detection models? Discover a wide variety of high-quality object detection datasets to fuel your AI projects.
Data-Centric AI: A Guide to Improving ML Performance Through Data
Learn how the benefits of Data-Centric AI, a new paradigm focusing on improving data quality applies to computer vision.