End-to-End Repeatable MLOps for Computer Vision
Any enterprise ML pipeline should automate various steps in the ML lifecycle. Such automation is usually achieved by compartmentalising each step as a stan
Picsellia Team
·7 min read
Ready to build computer vision?
Go from raw images to production models. Free trial, no credit card, cancel anytime.
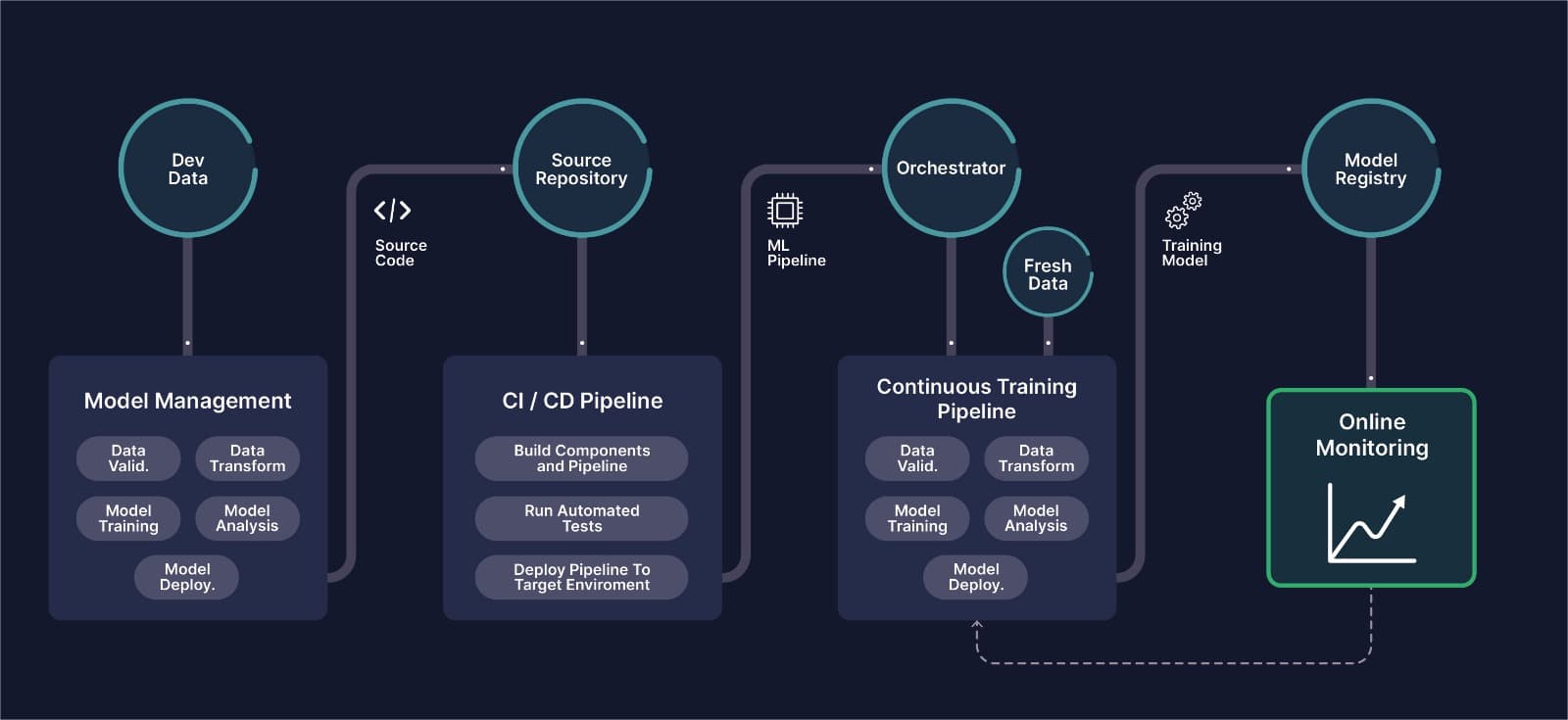
Automated Pipeline and Compartmentalization
 End to end repeatable mlops for computer vision
End to end repeatable mlops for computer vision
Primarily, any enterprise ML pipeline should automate various steps in the ML lifecycle. Such automation is usually achieved by compartmentalising each step as a stand-alone service rather than building a monolithic Jupyter notebook or script with all the steps implemented in a single programming module.
For instance, in an enterprise computer vision application, data ingestion can be managed by an independent service supervised by a separate team of data annotators and ETL experts. This service can then communicate with the data cleaning, wrangling, and validation service through an API maintained by a separate data team. The highly skilled team of computer vision experts can utilize the processed data pipeline to build, train, and evaluate CV models. Finally, specialized CVOps experts with CI/CD skills can build a service to deliver the model in production and monitor it around the clock. The pipeline is, therefore, a collection of such services that run independently but operate in a coordinated manner to ensure that an AI model works seamlessly. This process is analogous to working with containers in software development. Doing so with machine learning would save an organization an incredible amount of time and money while minimizing inconsistencies and avoiding duplications.
Now, the real question is: whether an organization should build such a complex pipeline from scratch, opt for vendor-managed MLOps tools, or leverage open-source frameworks. Each option needs to be evaluated against the abovementioned characteristics to avoid common MLOps pitfalls and make an informed business decision.
-
Flexibility: Build or buy – the platform must be flexible enough to cater to different situations and edge cases. Each case may require different modeling techniques or libraries, along with varying data requirements. A custom-built platform offers the flexibility to add more features and modules to the CVOps tools in-house. But a managed CVOps platform is more rigid to any change and can only be added by the vendor.
-
Interoperability: The market for MLOps tools is still evolving. An open-source tool that automates data ingestion and data cleaning may not support training or deployment. However, the open-source tool should have the ability to operate smoothly with the custom-built training and deployment modules. On the other hand, a managed MLOps tool is typically not interoperable.
-
Compatibility: An effective CVOps tool must integrate with the organization’s existing set of business tools. A custom-built pipeline can ensure compatibility across the stack, but it costs a lot. Also, the required talent may not be at the company’s disposal. They would have to execute an expensive hiring cycle to onboard high- quality resources that can execute pipeline implementation. On the other hand, a managed CVOps tool may not offer relevant connectors for a company’s existing stack by default.
-
User-friendliness: The tool’s user experience and design should be seamless to enable ease of use for different team members. In a custom-built CVOps pipeline, the team has full control over the UX elements. They can adapt it as per internal company guidelines and preferences. However, managed tools are designed by vendors to offer a generic UI and UX experience, which may not be suitable for specific business requirements.
-
Community or Vendor Support: One of the advantages of open-source tools is their extensive community support. However, community support is not always helpful when it comes to implementing complex business use cases. A vendor-managed MLOps platform offering expert consultation may be more suitable in this case. But, depending on the quality of their customer support, it can take some time to reach them.
A Word on Open-Source CVOps Tools–Some Common Issues
An open-source CVOps pipeline is like a jigsaw puzzle. If a business can put the correct pieces together, it can achieve a seamless ML development, deployment, and monitoring experience. For many businesses, particularly small to medium-sized, going for open-source tools seems viable due to negligible costs. However, enterprise- scale companies can find it challenging to piece together an end-to-end framework that can scale as per business requirements without causing any significant issues.
Regardless of the company’s size and business requirements, open-source MLOps and CVOps present the following problems:
-
In general, MLOps open-source tools, and particularly for CVOps, don’t offer an end-to-end solution. Some tools may offer data-processing automation, while others may only be used for automated deployments.
-
It can become extremely difficult to make multiple open-source tools work together. Therefore, compatibility and interoperability can be some real challenges. Different tools use different types and versions of data and modeling libraries which can be non-compatible with each other. Moreover, open-source tools at times use obsolete packages, which, when discovered, cause more harm than good.
-
On the flexibility front, an open-source tool designed to handle, let’s say, tabular data cannot be easily modified to handle image data. Even a CV-specialized open-source tool may have missing features like parsing videos and converting them into images. The company employing such tools would have to spend significant resources to implement its desired functionalities.
-
Not every data scientist and ML engineer is well-versed in the implementation code of different open-source tools.
Which CVOps Tool Should You Choose? – Custom-Built, Open-Source, or Vendor-Designed
The company’s CV architect or executives must make a careful decision based on their business requirements and the resources at their disposal. Though open-source tools are cost-efficient, they present many issues that we have discussed above. Particularly on an enterprise scale, open-source tools are not a viable option.
An enterprise company with enough resources and flexible product delivery can choose to build its custom CVOps tool. However, they must ensure that the tool is flexible, compatible, interoperable, scalable, and user-friendly. They need to document all of their implementation processes to enable ease of use across teams. Often, companies could employ a support team to maintain the tool.
While a custom-built tool is an option, managed CVOps platforms can have more favorable benefits than custom and open-source platforms. Vendor-managed solutions are fully end-to-end with an integrated pipeline that offers all ML operations from data ingestion to model deployment and monitoring. Also, vendors have specialized personnel working on the operational side, which leads to minimal infrastructure setup, installation, and support issues.
An organization simply needs to communicate its requirements to the vendor, and everything else will be taken care of. Moreover, when opting for a managed solution, it is not just the platform that is being bought. Rather, it is a strategic partnership with a vendor that is important for the success of the CV pipeline.
However, with managed solutions, the downside is that the source code is almost inaccessible, and making extensions can be difficult. If the company wants to add an extra feature, then the usual pathway would be to request the vendor. This can take time, and if the fundamental requirements of the ML system change altogether, it would mean that an organization might get locked in, and switching may not be an option.
To avoid such issues, it should be ensured that vendors provide extendible solutions with loosely coupled components. This allows the organization to merge the platform with its own stack to ensure seamless machine learning operations.
Why Picsellia?–A Completely Automated CVOps Stack
 End to end repeatable mlops for computer vision
End to end repeatable mlops for computer vision
Picsellia offers a state-of-the-art, fully managed CVOps platform that includes the following CV operations:
- Dataset Management
Centralize unstructured images and videos to enable greater collaboration and minimize inconsistencies.
- Experiment Tracking
A complete experiment tracking toolkit to facilitate hyperparameter tuning and obtain the best AI model.
- Model Deployment
Immediately put models into a serverless production environment with 24/7 uptime.
- Model Monitoring
Real-time model monitoring to identify edge cases and early detection of model degradation.
- Automated Pipelines
Automate and orchestrate the entire computer vision project lifecycle.
With Picsellia’s cost-efficient solution, small, medium, and enterprise companies can significantly reduce ML pipeline failure rates and scale their application as per business requirements.
Curious about MLOps for computer vision? Download our white paper and learn more about them!
Related from Picsellia
Track every experiment
Log metrics, parameters, and artifacts automatically. Compare runs side by side and ship better models faster.
See Experiment TrackingAutomate your ML pipelines
Set up continuous training and deployment with automated triggers, shadow deployments, and feedback loops.
Explore Automated PipelinesStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles

From Computer Vision to Industry 4.0: How Scortex Is Shaping Automated Visual Inspection
Discover how Scortex leverages AI and computer vision for automated visual inspection, from defect detection to anomaly detection and real-time insights.

Mastering Data Annotation for AI Projects in 2025
This article will discuss the importance of data annotation in AI and the best practices and strategies for overcoming labeling hurdles.

2025 Trends in Computer Vision: What to Expect
Learn about the upcoming Computer Vision trends in 2025.