How We Built A Dataset Visual Similarity Search Feature
Learn how we built a dataset visual similarity search feature with embeddings and Qdrant.
Picsellia Team
·8 min read
Ready to build computer vision?
Go from raw images to production models. Free trial, no credit card, cancel anytime.
As we examined in our last article** **some of the key features of an efficient data management system are data exploration and filtering. We have defended this for a long time now, but we never had the time to add this feature to our platform. These times are gone!
In this article, we’ll walk you through the general concept of image embedding, and how we implemented our scalable visual search feature to find similar images across millions of images for multiple clients at the same time.
What’s an Embedding?
Embeddings are a way of mapping discrete variables to continuous numbers. In the context of neural networks, embeddings are low-dimensional vector representations of categorical variables.
Neural network embeddings allow for close neighbors in the space and can be used to make recommendations based on user interests, cluster categories, or input into machine learning models for supervised tasks that need vectors as input, like classification tasks that use labels learned from labeled data (such as spam detection).
Embedding visualization is useful as it lets people see concepts and relations between different categories within a given dataset, more clearly than traditional methods do, by reducing dimensionality without losing information about what is being represented.
Here, our goal is to leverage embeddings to quickly identify similarities in images (without a-priori info on the similarity features).
How to Generate Image Embeddings?
Transformation Based Descriptors
 How we built a dataset visual similarity search feature
How we built a dataset visual similarity search feature
You have multiple strategies to generate your image embeddings. The whole point is to select a set of features that will represent your images in the best way possible. To do so, you can use some classical descriptors like SIFT (Scale-Invariant Feature Transform) or SURF (Speeded Up Robust Features). These approaches focus on point of interest identification and matching, which is a great way to find similar objects in an image that are in different positions.
Here is a good introduction to SURF!
To generate them, you can use OpenCV. Here is a link to an OpenCV tutorial on SURF computation.
Please note that SURF and SIFT algorithms are patented and can’t be used commercially, a great alternative can be ORB (Oriented FAST and Rotated BRIEF).
Convolution Nets Based Descriptors
As we saw, classical descriptors are great to identify any kind of transformation and match two images that look a lot like. But, if you want to create a more symbolic search for similarity, you’ll need another method.
That's why convolutional neural networks are so powerful. In the past ten years, deep learning models have achieved very high accuracy levels to classify pictures. These deep learning ConvNets can be used to extract features from pictures that are invariant; not only when it comes to geometric transformation, but also in the instance itself! What does this mean? Two images of the same category will have the same representation.
 How we built a dataset visual similarity search feature
How we built a dataset visual similarity search feature
The goal is to use the vector of features generated by the ConvNet features extractor, to build a vector space corresponding to all the images of your set.
There are so many ConvNet models out there that it has become a complex task to decide which one to use. When building a scalable visual search feature, you will need to generate various embeddings over time for your entire data lake. Thus, it’s a good idea to find a great trade-off between the size of the model, inference time and accuracy.
 How we built a dataset visual similarity search feature
*Source: AI Google Blog *
How we built a dataset visual similarity search feature
*Source: AI Google Blog *
The latest EfficientNet architectures released by the Google team are a great choice since the number of parameters (thus, the size and inference time) of the model is significantly lower than the ones of ResNet, for example. So an EfficientNet-b0 can be a good fit for our use case.To generate the embeddings, we are using the img2vec Python package.
 How we built a dataset visual similarity search feature
How we built a dataset visual similarity search feature
Now that we have everything we need to generate our embeddings, we can think about the similarity search strategy.
How to Implement Visual Search?
Once we have embeddings for all our images, we need to create an index for each data. Here, as we are building a feature to interact with the pictures stored in Picsellia’s data lake, we are going to use our data’s UUID as an index.
 How we built a dataset visual similarity search feature
How we built a dataset visual similarity search feature
Next, we want to find, given an index, the N most similar pictures.
Brute Force Search (Euclidian, Cosine, etc.)
A simple way to implement a similarity search is to compute the distance of a given feature vector between all the other vectors and then select the N closest neighbors. For this approach, you only need to consider the distance that you want to compute, vector similarity is often computed through cosine distance.
 How we built a dataset visual similarity search feature
How we built a dataset visual similarity search feature
The pseudo-code associated with this search would be:
x = target_vector
for all indexes:
*** compute cosine_distance between x and the index***
extract the K nearest neighbors
This approach is considered brute force since the complexity of the search is linear (as shown in the graph below). For us, it’s completely impossible to use such approaches as we manage millions of images for multiple clients.
 How we built a dataset visual similarity search feature
How we built a dataset visual similarity search feature
HNSW (Hierarchical Navigable Small World Graphs) – a Smarter Approach
This algorithm has been introduced in the research paper “Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs” by Yu. A. Malkov, D. A. Yashunin.
You can find the Python bindings to the C++ implementation here.
The algorithm generates a graph where every node is a feature vector linked to its closest neighbor. When looking for the K nearest neighbor, you just have to navigate the graph and extract the K closest point.
The objective is to create an approximation of the search to reduce the number of computations performed and reduce the computational complexity of the search. In short terms, it allows us to search inside a 1m index’s database in milliseconds!
 How we built a dataset visual similarity search feature
How we built a dataset visual similarity search feature
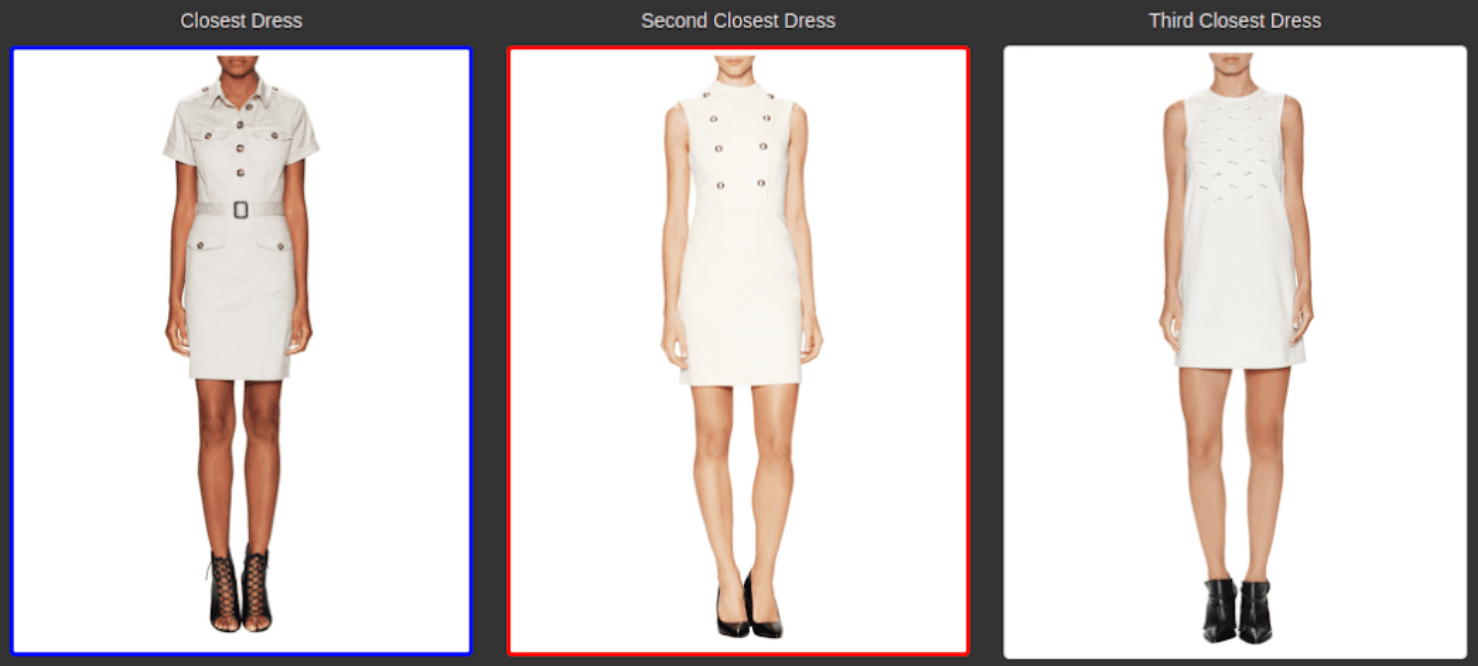
Now let’s wrap it up by using Picsellia!
Behind the Scene of Picsellia’s Visual Search Implementation
At Picsellia, we provide a Data Management platform to supercharge cloud object storage with indexing, filtering, search, visualization, and more. That’s why it makes sense for us to build some visual search features.
 How we built a dataset visual similarity search feature
Picsellia's Data Lake
How we built a dataset visual similarity search feature
Picsellia's Data Lake
Pretty great speed right? Well, let’s see how we built this.
Our Requirements
To meet our development standards, our visual search feature needs to have these characteristics:
- Be standalone in a web microservice
- Work on multiple siloed indexes collection for every client
- Browse into millions of rows in milliseconds
- Have a non-linear complexity
These are essential needs, but if we want to develop everything in-house, we would have to put some effort into building a scalable solution meeting these requirements. Hopefully, as the neural search field is booming, there are many solutions on the market to address these requirements.
Introducing Qdrant
 How we built a dataset visual similarity search feature
Qdrant
How we built a dataset visual similarity search feature
Qdrant
“Qdrant (read: quadrant) is a vector similarity search engine. It provides a production-ready service with a convenient API to store, search, and manage points–vectors with an additional payload. Qdrant is tailored to extended filtering support. It makes it useful for all sorts of neural networks or semantic-based matching, faceted search, and other applications.
Qdrant is released under the open-source Apache License 2.0. Its source code is available on GitHub.” *Source: Qdrant’s documentation. *It implements a custom implementation of the HSNW algorithm allowing us to add extra filters to our query, and giving us complete modularity on our search, which is great for us!
Their open-source solution comes packaged in a single Docker image exposing a web server to communicate with. For our tech team, it’s perfect as we can wrap it up in a custom service that will generate the embeddings and easily store them inside the Qdrant collection.
In addition, they provide a set of APIs to register a new index and a corresponding id, to later retrieve the elements. We are using the unique id of the picture stored on our buckets, ensuring smooth communication between our services.
Implementation
The key phase is embeddings' creation, and how to do it at scale without impacting the overall performance of the search engine and platform. To do so, we are using asynchronous tasks with Celery to queue all the work and keep the embeddings creation on CPU.
 How we built a dataset visual similarity search feature
How we built a dataset visual similarity search feature
Wrapping up
This new implementation allows us to generate embeddings for millions of images asynchronously without any impact on the overall performance of Picsellia’s products.
Once the embeddings are indexed and linked to our unique image ID, it gets really easy to find similar images in your dataset in no time! This makes dataset exploration as easy as ABC for you!
If you want to benefit from an entire Data Management suite packaged inside an end-to-end Computer Vision platform, just claim your trial!
Related from Picsellia
Ship vision AI 10x faster
Picsellia is the end-to-end MLOps platform for computer vision — from data management to production deployment.
See the PlatformCentralize your visual data
Store, search, and organize millions of images in a single place with tags, metadata, and visual similarity search.
Explore the DatalakeStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles

Introducing Picsellia Atlas: An Open-Source AI Co-Pilot for Advanced Vision AI Development
Picsellia Atlas: an open-source AI co-pilot to streamline custom Vision AI development, boosting data quality, model precision, and workflow efficiency.

Introducing Picsellia Community Edition
Accelerate your VisionAI journey with Picsellia Community Edition, the free version of Picsellia.

Optimise Data Exploration with Enhanced Visual Search
Discover how visual search changes image data exploration, enabling efficient cleaning, object detection, and image- and text-based searches