What is video annotation for computer vision?
Looking for video annotation and computer vision services? Enhance your AI algorithm models with accurate and comprehensive data.
Picsellia Team
·9 min read
Ready to build computer vision?
Go from raw images to production models. Free trial, no credit card, cancel anytime.
Video labeling, or video annotations, is the essential component of the video dataset for training computer vision (CV) models. The video annotations contain information about pixel areas from a continuous stream of pixels relevant to a computer vision task. The processes and methods for annotating video are different due to the complex nature of video data; they can present an added layer of intricate information that improves data quality and robustness, increasing the performance of computer vision models for various computer vision tasks.
This article focuses on video annotation's unique peculiarities for computer vision tasks that require tracking objects for understanding.
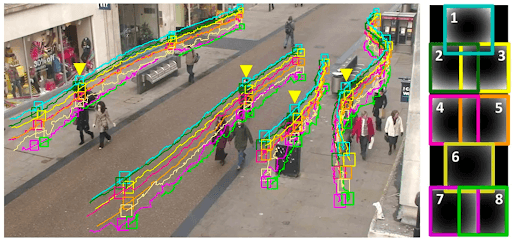
 Video annotation 65afd208f5a96b7b71ce940d zxiwuuqui3bidzbwm63t3sad0oq4qryge6kkm9mxespa 7fnvfjhtqks xfa pxjdwljg3jruic9j0fufdx4vwqazram35jrpbpp0cjh6zw5glxwahpsleet4h9n9mhort4wyovkaldsdzl06w jexu
video annotation street
Video annotation 65afd208f5a96b7b71ce940d zxiwuuqui3bidzbwm63t3sad0oq4qryge6kkm9mxespa 7fnvfjhtqks xfa pxjdwljg3jruic9j0fufdx4vwqazram35jrpbpp0cjh6zw5glxwahpsleet4h9n9mhort4wyovkaldsdzl06w jexu
video annotation street
What is the purpose of video annotation?
Video annotation in computer vision entails carefully inserting a wide range of labels into the video frames by labeling or masking relevant pixels for everything, from simple object detection to complex object tracking tasks. You can enhance the creation and effectiveness of computer vision systems by utilizing detailed video annotations.
Video annotations identify objects and give more information about the action and context of an object, such as the likely behavior and trajectory of the object based on the environment it is acting within. Consider a scenario where a single snapshot of an athlete throwing a javelin. It omits information on the trajectory and speed of a thrown javelin. In contrast, if you have a videotape of the event, a CV model could evaluate the sequence of frames, providing insights into the precise direction of the javelin's trajectory and facilitating the estimation of its speed relative to other elements in the footage. This intricate ability underscores the edge of using video data over static photos when annotating for specific CV tasks that require comprehending the dynamic features of movement.
Video Annotations for Object Tracking
Video annotation can significantly improve the ability of computer vision models for tasks like object tracking, event detection, and action recognition. These CV tasks require consistent identification of the same objects in multiple frames. Since the training data should already have that intricate property or ability, object tracking makes up for the need for robust object detection methods with video annotation.
Object detection tasks focus on identifying and localizing multiple objects within an image or a video frame. It is primarily concerned with analyzing individual frames in isolation. Each frame is processed independently, and the goal is to identify objects within that frame. This is both computationally and time-intensive for robust object detection methods. For one, the available frame rate might not be in real-time, or you might miss frames. Therefore, the technique lacks handling overlapping objects, varying object scales, and occlusions.
Object tracking tasks extend this concept by maintaining the identity of objects across multiple frames in a video sequence. Object tracking is often applied as a subsequent step to object detection. Once objects are detected in the first frame, it initializes tracking them across successive frames.
While maintaining the identity of an object from one frame to the next, it deals with challenges like object appearance changes and occlusions. Object tracking considers the temporal continuity of objects. It is crucial in scenarios where the goal is to monitor the movement or behavior of specific objects over time, such as in surveillance, autonomous vehicle systems, etc.
In computer vision, the type of annotation and data format used influence the efficiency and accuracy of the models when performing specific tasks. Robust object tracking relies on video annotations. Their data helps your models deal with context, mobility, and even partial visibility, so your tracking performance will be precise, robust, and dependable.
What is the difference between image and video annotation?
CV models are typically trained with annotations obtained from images or video. While you can use image and video annotations to develop models for the same computer vision model task, such as object detection and object segmentation, they have distinct approaches, processes, benefits, and challenges.
Image annotation contains information about a specific object class, but the annotation information for each object is from static frames of different examples in different contexts. Computer vision models cannot fully develop an understanding of the object's action because other parts of the frame aren't provided. Embedding that level of knowledge into CV models with image annotation would require collecting frames from the same content and annotating them serially in the sequence of occurrences, which is a very cumbersome process.
Ordinarily, video annotation generally requires more effort due to optical flow (image motion) and occlusion complexity to derive meaningful insights about the action and context of the object in video data. Video annotations leverage the interpolation technique to extract sequential information and understanding. It tracks the objects moving and changing across multiple frames, speeding up the annotation process. Technically, the annotation of objects is assigned IDs at their first appearance in any sequence of frames. The ID of an object from the previous frames is used to track and predict its location in the next frame. This is known as object identification and re-identification.
“Optical flow and temporal context are critical aspects of video annotation that distinguish it from image annotation.”
How do you annotate a video on computer vision?
Video annotations are extracted manually or automatically with the aid of annotation tools. Annotators must consider more information and make inferences based on temporal context by analyzing optical flow and changes in object appearances across frames. It starts by sampling the video into image frames, which typically involves taking a snapshot of the video at various points in time. This sampling is done by taking snapshots of the video frame rate per second, and choosing an optimal extraction rate of the frame per second is crucial to data quality. Looking through the snapshots is similar to looking through a moving image.
Let's say you have a 16-second video and are set to take snapshots at 30 frames per second. You would end up with 480 images of a specific task, with dynamic positions and instances. It is recommended to use a lower FPS, such as two frames per second, for object recognition activities to produce rarity and low repetition; nevertheless, for video tracking tasks, it is advisable to explore utilizing a higher number of frames per second FPS to aid in embedding optical flow. Using a mask or required annotation type (i.e., bounding boxes, ellipses, polygons, keypoints, 3D cuboids, etc.) for the computer vision task, you can then annotate objects and interpolate the annotation across keyframes.
Annotators or annotation tools help with occlusion problems in computer vision tasks by looking at optical flow and alterations in object appearances across consecutive frames. This includes detecting obstructed objects and inferring their presence and movement, even partially hidden ones. Furthermore, annotators can classify occluded zones by highlighting locations where items are expected to be found, utilizing contextual information and motion signals. The ability to track occluded objects allows for the preservation of object identity, guaranteeing consistency in recognition even when objects are partially or temporarily concealed from view. These functions improve the robustness of computer vision systems.
Features of Video Annotation Tools
There are many critical criteria to consider when choosing an annotation tool for your project. Efficiency and operational factors are two major pillars of concern. It all depends on how complicated your video annotation mission is. Given that video annotation tools have different features, there are efficiency tradeoffs for use cases involving anyone. Here are some features that some popular video annotation tools provide:
- Support of any annotation format
- Support for all annotation types, boxes, polygons, polylines, key points, and primitives.
- Simplified human review pipelines to increase training data and project management efficiency
- Supports interpolation of shapes between keyframes
- Rendering and annotation of videos and image sequences of any length
- Provision of an easy way to annotate videos quickly while maintaining a high frame rate, good resolution, and supporting numerous sequences
- Support for intricate label sub-classifications through the provision of robust ontology features
- Automated error highlighting to ease the process of debugging and fixing issues.
On the operational part, some solutions are more suited to individual annotators. In contrast, others provide team-friendly collaboration features like real-time updates and access control, so it all comes down to team size and collaboration needs. Financial constraints should also be carefully considered. While open-source solutions can be inexpensive, they may necessitate technical knowledge. On the other hand, premium products provide more functionality and support, but they come with a licensing price. Finally, choose a solution that works well with the machine learning frameworks and data management systems you already use; this will provide a smooth transition from one system to another.
Conclusion
Unlike the static portraits of images, videos present a dynamic world where occlusions, motion blur, and temporal complexities dance in the shadows. This article has shed light on the unique peculiarities of video annotation for tasks demanding object tracking. We've explored the intricate interplay between temporal information, motion cues, and object interactions, highlighting how they differ from the snapshot simplicity of image labeling. We've witnessed how even subtle nuances in an annotation can profoundly impact understanding an object's journey within a video.
In the next part of this article, we'll traverse the diverse landscape of video annotation platforms. Embark on a rigorous benchmarking expedition, charting the strengths and weaknesses of various video annotation tools. We'll pit automation against precision, collaboration against efficiency, and cost against capability, unveiling the tradeoffs at every tool's heart. Dive deeper into the best video annotation tools.
Related from Picsellia
Annotate faster with AI assistance
Picsellia's labeling tool supports bounding boxes, polygons, and segmentation masks with built-in AI assistance to speed up annotation.
Explore the Labeling ToolOrganize and version your datasets
Version, slice, and manage datasets with full traceability — from raw images to production-ready splits.
Explore Dataset ManagementStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles

From Computer Vision to Industry 4.0: How Scortex Is Shaping Automated Visual Inspection
Discover how Scortex leverages AI and computer vision for automated visual inspection, from defect detection to anomaly detection and real-time insights.

Mastering Data Annotation for AI Projects in 2025
This article will discuss the importance of data annotation in AI and the best practices and strategies for overcoming labeling hurdles.

2025 Trends in Computer Vision: What to Expect
Learn about the upcoming Computer Vision trends in 2025.