Qu'est-ce que le Data Drift et comment le detecter en vision par ordinateur ?
Le data drift survient lorsque le dataset utilise pour entrainer votre modele ne reflete pas les donnees que vous recevez en production, entrainant une baisse de performance de votre modele.
Picsellia Team
·6 min read
Mettez votre MLOps en pratique
Arretez d'assembler des outils. Adoptez une plateforme CV de bout en bout avec automatisation integree.
Le data drift survient lorsque le dataset utilise pour entrainer votre modele ne reflete pas les donnees que vous recevez en production. C'est a ce moment que votre modele commence a se comporter de maniere etrange et a sous-performer.
La difference entre les donnees d'entrainement et de production peut etre causee par de multiples facteurs. Il peut s'agir d'une creation de dataset inexacte, comme l'utilisation de donnees ouvertes non adaptees a votre cas d'usage. Par exemple, si vous utilisez un dataset routier construit en Europe, il sera tres different des routes americaines. Si vous executez vos modeles de vision par ordinateur sur des routes americaines, cela entrainera probablement un data drift.
Une autre raison pourrait etre l'intervalle de temps entre la collecte de donnees a des fins de test et de validation et leur deploiement dans des scenarios en temps reel. Des exemples seraient une erreur dans la collecte de votre dataset initial, ou des cas de saisonnalite lies a la saison durant laquelle vous avez collecte votre dataset initial (par exemple, donnees d'hiver/donnees d'ete).
Comment detecter le Data Drift
Lors du deploiement d'un modele de vision par ordinateur, il est important de surveiller regulierement ses performances. Si les donnees utilisees pour entrainer votre modele changent ou deviennent obsoletes, son efficacite peut etre affectee. C'est ce qu'on appelle le data drift.
Supposons que nous ayons un modele de vision par ordinateur construit a partir d'un dataset de 100 races de chiens differentes, et que nous voulions savoir si notre precision diminue en raison du data drift. Pour cela, nous devrons enregistrer toutes les nouvelles images et predictions ingerees par notre systeme de boucle de retour. Ensuite, nous devrons examiner, modifier ou valider ces predictions.
Vous disposez maintenant de toutes les donnees necessaires pour comparer les predictions initiales avec celles modifiees et calculer vos metriques de performance pour verifier si elles sont au-dessus de vos metriques de performance moyennes. FACILE, N'EST-CE PAS ?
 What is data drift and how to detect it with mlops
What is data drift and how to detect it with mlops
Eh bien... Bien que ce soit l'approche ideale, cela signifie que vous devez donner acces a de nombreuses personnes afin de valider toutes vos predictions en temps reel. En d'autres termes, vous aurez besoin d'une main-d'oeuvre suffisante pour examiner toutes les predictions.
Cela suggere que nous devrions envisager des methodes heuristiques pour detecter le data drift de maniere non supervisee. Pour ce faire, nous allons introduire une metrique disponible nativement si vous utilisez les solutions de Picsellia pour le deploiement et le monitoring.
Detection de drift par Kolmogorov-Smirnov
Le test de Kolmogorov-Smirnov (test KS) est un test statistique qui ne necessite aucune entree utilisateur et est utilise pour comparer des distributions de probabilite continues ou discontinues a une dimension. Il peut etre applique soit pour comparer la distribution d'un echantillon avec la distribution de probabilite de reference (KS a un echantillon), soit pour comparer deux echantillons de distributions de populations ayant une variabilite egale, afin de determiner s'ils sont issus de distributions de populations differentes aux parametres inconnus.
La methode porte le nom d'Andrey Kolmogorov et Nikolai Smirnov, qui l'ont proposee pour la premiere fois pour une utilisation dans de tres grandes tables de chiffres aleatoires generes par des humains.
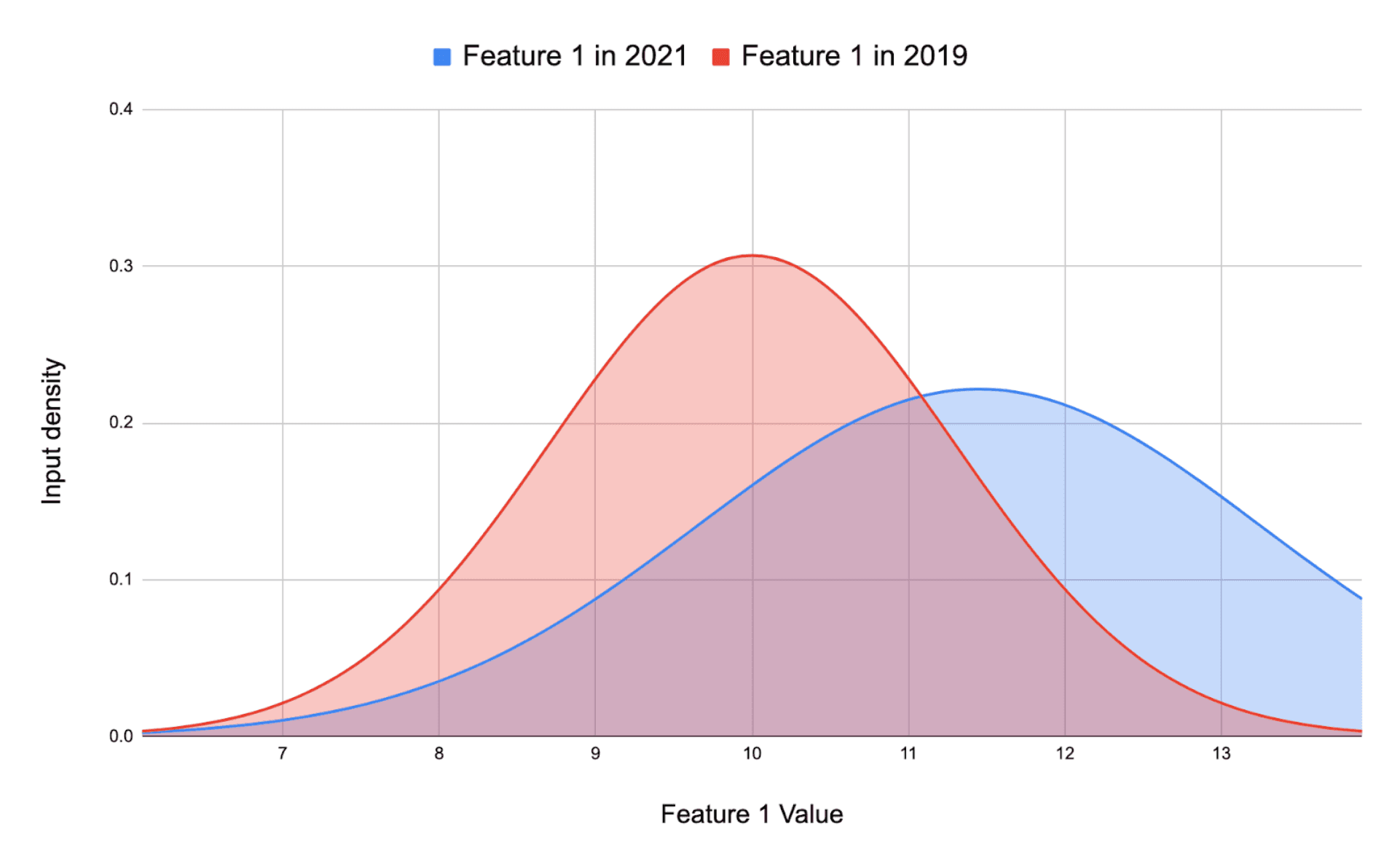
La statistique de Kolmogorov-Smirnov est utilisee pour quantifier la distance entre les fonctions de distribution des donnees du monde reel et les distributions des donnees du jeu d'entrainement.
Vous pouvez trouver plus d'informations sur la detection de drift KS dans la documentation bien detaillee de la bibliotheque seldon ici.
En resume, vous obtiendrez une liste de p-values pour votre jeu d'entrainement et vos donnees du monde reel, et la distance entre ces deux courbes vous indiquera s'il y a un drift.
 What is data drift and how to detect it with mlops
Ici, il n'y a pas de drift.
What is data drift and how to detect it with mlops
Ici, il n'y a pas de drift.
 What is data drift and how to detect it with mlops
Ici, il y a un data drift.
What is data drift and how to detect it with mlops
Ici, il y a un data drift.
Comment gerer le Data Drift ?
Comme nous l'avons dit precedemment, le data drift se produit lorsque vous entrainez vos modeles sur des images trop differentes des donnees du monde reel que votre modele de vision par ordinateur voit en production. Maintenant que nous savons comment le detecter, comment pouvons-nous le corriger le plus rapidement possible ?
Il y a plusieurs elements a considerer avant de prendre une quelconque action. Supposons que vous ayez des annotations pour toutes ces nouvelles images detectees comme data drift. Dans ce cas, il est judicieux de ne pas appuyer aveuglement sur "re-entrainer".
Le data drift indique que le flux d'images en entree a change, mais comment et pourquoi ?
La premiere chose a verifier est les donnees entrant dans votre boucle de retour. La pire chose qui pourrait arriver serait d'ingerer des images vierges ou deteriorees dans votre pipeline de donnees, causees par une erreur. Cependant, verifier cela est facile si vous avez construit un processus efficace de visualisation de la boucle de retour.
Si la qualite de vos donnees est correcte, alors vous devriez verifier comment votre modele performe pour votre cas d'usage metier specifique.
Quand on parle de data drift et de prediction drift, on pense generalement a une baisse de performance du modele. Le modele est-il toujours capable de generaliser ses predictions ? Ou le data drift deteriore-t-il completement les performances de votre modele de deep learning ?
Il pourrait y avoir deux scenarios differents concernant les performances de votre modele.
- Si le modele performe toujours comme attendu
→ Envisagez d'ajouter un pourcentage des nouvelles images ingerees par votre boucle de retour dans votre jeu d'entrainement et de re-entrainer votre modele. De cette facon, vous aurez une meilleure representation de la realite tout en conservant votre precision passee.
- Si le modele ne performe plus comme attendu
→ Cela signifie que les donnees utilisees pour l'entrainement et la validation n'etaient pas du tout representatives de la realite de votre cas d'usage. Dans cette situation, je suis desole, mais vous devrez reconstruire un dataset entier avec les images nouvellement ingerees (si vous en avez suffisamment), ou simplement attendre d'avoir une quantite suffisante de donnees pour re-entrainer vos modeles.
Points cles a retenir
Le data drift et le concept drift sont deux des problemes les plus courants dans les applications de vision par ordinateur. Alors que le data drift fait reference a des changements dans la distribution des donnees d'entrainement, le concept drift fait reference a des changements dans la distribution sous-jacente du probleme lui-meme. Ces problemes peuvent entrainer la defaillance des modeles d'apprentissage supervise. Heureusement, il existe des outils pour detecter et attenuer ces problemes.
Si vous recherchez une plateforme qui vous aide a surveiller et automatiser votre boucle de retour pour toujours detecter les data drifts, restez a l'ecoute. Chez Picsellia, nous publierons une nouvelle version amelioree qui vous permettra de faire tout cela sur une seule plateforme. Si vous souhaitez en savoir plus sur nos fonctionnalites de monitoring et de pipelines automatises, contactez-nous !
Suggestions Picsellia
Automatisez vos pipelines ML
Configurez l'entrainement et le deploiement continus avec des declencheurs automatiques, des deploiements shadow et des boucles de feedback.
Explorer les pipelines automatisesOrganisez et versionnez vos datasets
Versionnez, decoupez et gerez vos datasets avec une tracabilite complete — des images brutes aux splits prets pour la production.
Explorer la gestion de datasetsRestez informe
Recevez les derniers articles sur la vision par ordinateur, le MLOps et l'IA directement dans votre boite mail.
Articles associes
Le coût du changement d'outils dans les pipelines de vision par ordinateur
La surcharge liée aux outils n'est pas additive, elle se cumule. Découvrez comment le changement de contexte entre outils ML coûte aux équipes CV des centaines d'heures d'ingénierie par an.

Top 5 des outils de suivi d'experiences pour la vision par ordinateur
L'IA est generalement obtenue par des processus iteratifs et experimentaux tels que la modification du modele, l'execution de multiples experiences et l'examen des resultats.

Pourquoi les outils MLOps classiques ne conviennent-ils pas a la vision par ordinateur ?
Les pipelines de vision par ordinateur necessitent un ensemble de processus exclusifs a la vision par ordinateur. C'est la que le CVOps entre en jeu.