Are Transformers replacing CNNs in Object Detection?
In the past decade, CNNs sparked a new revolution in computer vision. In 2020, ViTs gained a lot of attention. Are transformers replacing CNNs?
Picsellia Team
·12 min read
Ready to build computer vision?
Go from raw images to production models. Free trial, no credit card, cancel anytime.
In the past decade, CNNs sparked a revolution in computer vision. Deep learning won the top spot in many computer vision challenges, and many traditional computer vision techniques became redundant. In 2020, a new architecture, the Vision Transformer (ViT), gained much research attention. It showed promising results in outperforming SOTA CNNs in many image recognition tasks before beating them in more advanced tasks such as object detection and segmentation.
Are CNNs becoming redundant with the invention of Vision Transformers?
First, we will introduce the Vision Transformer architecture. Second, we will explain some essential differences between CNNs and ViTs. Then, we will dive into a quantitative comparison of the two architectures regarding performance, training data, and time.
TLDR
- CNNs are a more mature architecture, so it is easier to study, implement and train them compared to Transformers.
- CNNs use convolution, a “local” operation bounded to a small neighborhood of an image. Visual Transformers use self-attention, a “global” operation, since it draws information from the whole image. This allows the ViT to capture distant semantic relevances in an image effectively.
- Transformers have achieved higher metrics in many vision tasks, gaining a SOTA place.
- Transformers need more training data to achieve similar results or surpass CNNs.
- Transformers may need more GPU resources to be trained.
Transformers and Self-Attention
Initially designed for Natural Language Processing tasks, transformers are very efficient architectures for data that can be modeled as a sequence (e.g., a sentence is a sequence of words). It solves many issues other sequential models like Recurrent Neural Networks face. Transformers are made up of stacks of transformer blocks. These blocks are multilayer networks comprising simple linear layers, feedforward networks, and self-attention layers, the key innovation of transformers, represented with the “Multi-Head Attention” box in the image below.
 Are transformers replacing cnns in object detection
Schematic of a transformer block. Norm refers to a normalization layer, Multi-Head Attention is the self-attention layer, MLP is a fully connected layer. The plus signs represent some operation (e.g. concatenation) of an output with a residual connection. Source: [2]
Are transformers replacing cnns in object detection
Schematic of a transformer block. Norm refers to a normalization layer, Multi-Head Attention is the self-attention layer, MLP is a fully connected layer. The plus signs represent some operation (e.g. concatenation) of an output with a residual connection. Source: [2]
Self-Attention: A Technical Overview
Self-attention allows a network to extract and use information from arbitrarily large contexts directly. At the core of an attention-based approach is comparing an item of interest to a collection of other items in the sequence** to reveal their relevance in the current context.** The self-attention layer maps an input (x1 , x2,..., xn) into an output (y1, y2,..., yn). For example, the output y3 of the attention layer is a combination of a set of comparisons between x1 , x2 and x3 with x3 itself. The image below helps shed some light on this. Notice that only past elements of the sequence are used, i.e., x4 is not used for computing y3.
 Are transformers replacing cnns in object detection
*Mapping an input sequence x→ to an output sequence y→ through self-attention. All of the preceding inputs xi≤j including the one under investigation are used to produce an output yj. Source: [Dan. Jurafksy, James H. Martin: Speech and Language Processing (3rd ed. draft)] *
Are transformers replacing cnns in object detection
*Mapping an input sequence x→ to an output sequence y→ through self-attention. All of the preceding inputs xi≤j including the one under investigation are used to produce an output yj. Source: [Dan. Jurafksy, James H. Martin: Speech and Language Processing (3rd ed. draft)] *
Internally in the attention layer, a projection of input x to another space takes place. Three new latent variables, q, k, and v, are created by multiplying the initial variable xi with learnable matrices WQ, WK, WV or simply Q, K and V. Out of every input xi , 3 new variables qi, ki, vi are created. Formally:** qi =WQxi , ki=WKxi , vi=WVxi.**
Consequently, an attention score αi is calculated, which signals how much correlation/significance exists between two inputs xi, xj. The stronger their correlation under the sequence’s context, the bigger the attention score.
 Are transformers replacing cnns in object detection
Are transformers replacing cnns in object detection
Finally, the output of the attention layer yi is calculated as the weighted sum:
 Are transformers replacing cnns in object detection
Are transformers replacing cnns in object detection
In a Multi-Head attention layer, we have multiple such attention layers. The concept is that we can detect different semantic correlations between the inputs by using multiple arrays *Qi, Ki, Vi *(heads) instead of just one. For example, one head may detect geometrical relevancies while another texture relevancies. Hence, we can better interpret the dependencies present in a sequence.
Transforming Images Into Sequential Data
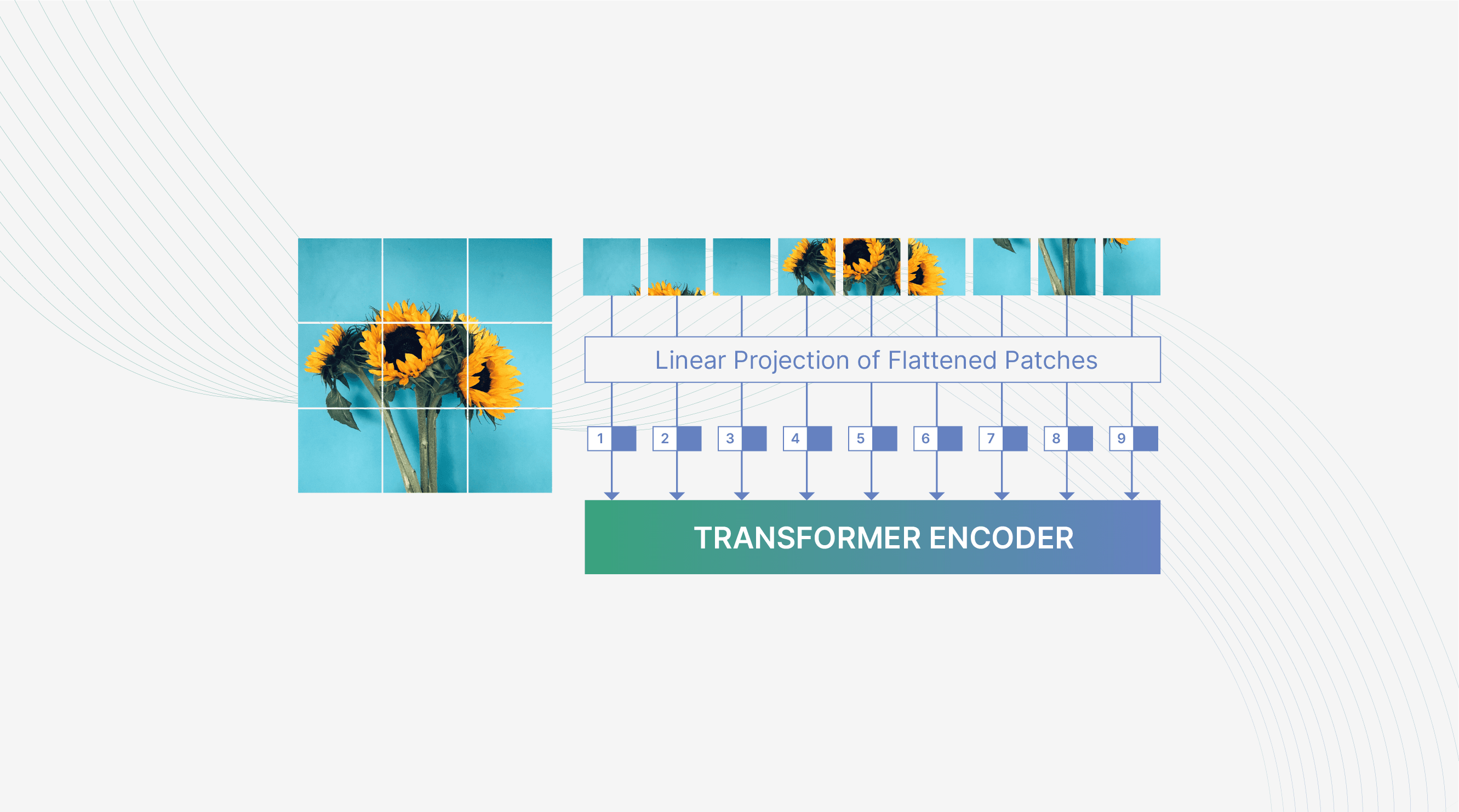
Everything we explained refers to sequential data, but images are represented as 3D matrices, not as 1D sequences. Here lies the difference between a traditional NLP Transformer and a Vision Transformer. It’s all about engineering an image to represent it as a sequence. The procedure is as follows.
- Split the original H x W x C image into 3D patches of dimensions P x P x C (P=16 was used in [2]).
- Flatten the 3D patches into 1D vectors of P2 x C elements each. A linear projection in another space is often used to create an input resembling text embedding.
- Concatenate the flattened vector with a value called positional embedding. This positional embedding helps keep track of the spatial order of the patches in the original image.
 Are transformers replacing cnns in object detection 63036fbd9f02db34e1a226c8 imagen 20baja
From a structured image to sequential data. The image is split into patches, patches are flattened and projected to another space. Finally, a positional embedding is concatenated to keep track of the spatial order, before feeding the input to the transformer. Modified by [2].
Are transformers replacing cnns in object detection 63036fbd9f02db34e1a226c8 imagen 20baja
From a structured image to sequential data. The image is split into patches, patches are flattened and projected to another space. Finally, a positional embedding is concatenated to keep track of the spatial order, before feeding the input to the transformer. Modified by [2].
After completing the steps mentioned above, the original image of H x W x C dimensions has been transformed into N vectors, where N = (H x W ) / P2 and each vector has P2C elements. Now, these vectors can be fed into the transformer block, and the attention mechanism will discover connections between different patches by computing their attention scores. If spatially apart patches are semantically connected, their attention score will be high, allowing the transformer to extract “Global” features instead of just “Local”. For example, a patch at the top of the image and one at the bottom might have a visual semantic correlation, achieving a high attention score.
**How and Why Are ViTs Different From CNNs? **
Before we dive deeper into our CNN vs. ViT comparison, we should first discuss some significant qualitative differences between the two architectures. In contrast to Vision Transformers, Convolutional Neural Networks (CNNs) treat images as structured pixel arrays and process them with convolutions, the *de facto *deep learning operation for computer vision. Through these trainable convolutional filters, CNNs create feature maps that are hidden representations of the original image, usually inexplicable to us. These feature maps are created through the convolution operation that affects only a small neighborhood (patch) of the image at a time. So we can consider it a local operation compared to the attention mechanism of the transformer.
Even though the convolution paradigm has provided excellent results over the past decade, it comes with some challenges, which Transformers aim to solve.
- **Not all pixels are equally important: **Convolutions apply the same filters over all pixels in an image regardless of their importance. However, foreground pixels are usually more important than background pixels in vision tasks like object detection or image recognition.
- **Not all concepts are shared across images: **Each convolutional filter “recognizes” specific concepts (e.g., edges, human eyes, shapes). All images will have edges, so an “edge filter” or a “shape filter” will always be valuable. Nonetheless, the same is not valid for a filter that detects human features like eyes, as any picture without a human will render the filter useless.
- **Convolution struggles to relate spatially distant concepts: **Each conv filter is bound to operate only upon a small neighborhood of pixels. Relating concepts spatially apart is often vital, but CNNs struggle to do so. Increasing the kernel size (filter) or adding more depth to the CNN mitigates the problem, but it adds model and computational complexity without explicitly solving the issue.
Vision Transformers offer a promising new paradigm that does not suffer from these issues due to its self-attention mechanism that operates at a “global” scale. The attention mechanism can semantically connect image regions far from each other, offering advanced image perception. Moreover, low attention scores are computed for unimportant pixels, showing more efficient representations.
Regarding training transformers, more so than in CNNs, self-supervised pre-training is used on vast datasets, and the knowledge is then transferred to the final downstream task. Self-supervision and Transformers are a very well-suited combination. CNNs can also be pre-trained with self-supervision but this learning method mainly gained ground with Transformers that were trained on huge unstructured text datasets and later on with vision transformers pre-trained on large image datasets.
**Comparison A: Performance **
On the task of object detection (COCO 2017 task), DEtection TRansformer (DETR) [4] and its variation, the Deformable DETR [4], are popular architectures. In [4], the authors compare the DETR with competitive baselines in object detection such as Faster RCNN and EfficientDet [7], which both rely on CNNs.
Results show that object detection with Transformers can offer improved detection compared to Faster-RCNN architectures when using the same backbones (ResNet 50, ResNet 101) for feature extraction. In particular, they achieve up to 4.7 improved AP. However, SOTA CNN-based object detectors like the EfficientDet-D7 are still superior, surpassing transformers on AP by 3.5 points on COCO 2017 vision task.
 Are transformers replacing cnns in object detection
Table modified by [4].
Are transformers replacing cnns in object detection
Table modified by [4].
Another study [5] suggested the Swin Transformer as a backbone model for object detection. They compared Swin with other SOTA CNN backbone models like ResNeXt (X101) on object detection and image segmentation tasks. They found that for networks with a similar number of parameters, a Transformer backbone achieves up to 3.9 increased AP75 in object detection and up to 3.5 increased AP75 in segmentation, making the transformer a better choice regarding performance.
 Are transformers replacing cnns in object detection
APbox refers to object detection performance, while APmask to image segmentation. Comparing different backbone models for object detection and image segmentation. R50 is ResNet-50, X101 is ResNeXt-101, Swin T/S/B are the tiny, small, big swin transformer architectures respectively. Source [5]
Are transformers replacing cnns in object detection
APbox refers to object detection performance, while APmask to image segmentation. Comparing different backbone models for object detection and image segmentation. R50 is ResNet-50, X101 is ResNeXt-101, Swin T/S/B are the tiny, small, big swin transformer architectures respectively. Source [5]
Comparison B: Train-Time and Data
In [2], the authors compared SOTA CNNs and their newly invented Vision Transformer architecture. The graph below compares the classification accuracy on ImageNet vs. the pre-training examples used. A significant conclusion comes out of these results. **Transformer architectures need more training data to achieve equal or improved accuracy than CNNs. **
Initially, only 10M images were used for self-supervised pre-training from Google’s internal image dataset JFT. Even big transformer architectures cannot match ResNet50’s performance, which has much fewer parameters when using 10M images. The largest transformer only matches the performance of CNN ResNet152 once 100M images are used for pre-training!
These results show that transformers are quite data “hungry,” and CNNs will offer better accuracy when data is scarce.
 Are transformers replacing cnns in object detection
Number of pre-training samples used during self-supervised pre-training vs. the final accuracy on the downstream task. Transformers are more data “hungry” compared to CNNs. Source [2].
Are transformers replacing cnns in object detection
Number of pre-training samples used during self-supervised pre-training vs. the final accuracy on the downstream task. Transformers are more data “hungry” compared to CNNs. Source [2].
Moreover, authors in [4] compared the training time in GPU hours required for the COCO 2017 challenge. Training a Faster-RCNN model with 42M parameters required 380 GPU hours, while an equivalent DETR model with 41M parameters required 2000 GPU hours! However, through improved training techniques and modifications in the architecture (Deformable DETR [4]), they managed to decrease the time to just 325 GPU hours, which shows that even though Transformers require much more training time on average, research in the field certainly brings enormous improvements!
Wrapping up
Despite being relatively new architectures, Vision Transformers have shown promising results. They have sparked huge research interest, so we can only expect improvements. ViTs can achieve new SOTA results in most vision tasks at the moment, surpassing CNNs. Additionally, an excellent study on ViT properties [6] showed that compared to CNNs, they are more robust against object occlusions, image perturbations, and domain shifts. Even after randomly shuffling image patches, ViTs can retain their accuracy levels impressively well.
There is no doubt that ViTs are excellent architectures with enormous potential for the future of Computer Vision. However, their vast hunger for data poses a big challenge for the average Computer Vision project. Since Transformers need 30M-100M images for self-supervised pre-training, it is almost impossible to train one from scratch unless you have the resources. If pre-trained models are available, fine-tuning your dataset is easier, but still, a lot of data is expected.
Regarding training time, Transformer architectures, on average, need much more computational resources. However, research in the field has already offered improved architectures that require training times similar to CNNs.
On the other hand, CNNs can still achieve comparable performance with fewer data. This trait still makes them relevant for most computer vision projects. CNNs are still a great choice and will probably tackle most tasks well enough. On top of that, CNNs are more mature, making them easier to build and train. To proclaim CNNs are already redundant is naive. We should be grateful that we have another great tool, the ViT, inside our computer vision architecture toolbox. But since not all problems are nails, you shouldn’t always be using a hammer.
References
[1] Visual Transformers: Token-based Image Representation and Processing for
[2] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE.
[3] Transformers in Vision: A Survey
[4] End to End Object Detection with Transformers
[5] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Related from Picsellia
Train models your way
Use pre-built pipelines for YOLO, SAM2, and more — or bring your own code with PyTorch, TensorFlow, or Hugging Face.
Explore the AI LaboratoryShip vision AI 10x faster
Picsellia is the end-to-end MLOps platform for computer vision — from data management to production deployment.
See the PlatformStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles

From Computer Vision to Industry 4.0: How Scortex Is Shaping Automated Visual Inspection
Discover how Scortex leverages AI and computer vision for automated visual inspection, from defect detection to anomaly detection and real-time insights.

Mastering Data Annotation for AI Projects in 2025
This article will discuss the importance of data annotation in AI and the best practices and strategies for overcoming labeling hurdles.

2025 Trends in Computer Vision: What to Expect
Learn about the upcoming Computer Vision trends in 2025.