Computer Vision Dataset Slicing
Discover dataset slicing, a technique used to divide large datasets into smaller parts to train and test models and improve model accuracy.
Picsellia Team
·6 min read

Organize your visual data today
Version datasets, manage annotations, and track lineage from one place.
Computer Vision (CV) deals with intelligent models that understand and interpret image datasets for various purposes. Some common CV tasks include image classification, object detection, and image segmentation. We use these models daily, e.g., unlocking your iPhone via faceID involves multiple CV-related processing.
Computer Vision also includes more complex applications, such as self-driving cars, which are trained over massive datasets. Handling such large-scale data is a significant problem for Computer Vision engineers. Images occupy substantially more memory than other data forms, and even a basic dataset is worth a few gigabytes. One common way to deal with such substantial files is dataset slicing. Let's talk more about it.
What is Dataset Slicing?
Slicing refers to dividing a dataset into multiple parts. The split can be performed randomly or according to a pre-defined key and can be performed across rows, columns, or any other dimension.
For example, if we have a table with 1000 rows and 5 columns (1000 x 5), we can slice this table across the columns and make divisions of 1000x3 and 1000x2. Or we can place slices along the rows forming two smaller tables with a 500x5 dimension for each.
The number of slices and the dimension to slice along solely depends on your use case.
Why Do We Slice Datasets?
Data Slicing is commonly performed for data science and machine learning tasks. Here’s why data science practitioners need dataset slicing.
1. Train-Test Split
During machine learning training, data is trained using some portion of the data and then tested on an unseen subset. This unseen dataset, called the test dataset, is generated by slicing the primary data into two parts. The larger set (usually 80% of the overall data) is called the training set, and the smaller (usually 20% of the overall information) is called the test set. The train set trains the model, and the test set evaluates it.
 Computer vision dataset slicing
**Source: Michael Galarnyk
Computer vision dataset slicing
**Source: Michael Galarnyk
2. Exploration & Analysis
One of the most common techniques for exploratory analysis is data masking and slicing. It is used to analyze specific parts of a dataset. Analysts may slice data across columns to view only the relevant fields or across rows when specific points are to be focused. Datasets that include time series are sliced at different intervals for time-based analysis.
3. Batch Processing
During neural network training, data is often divided into chunks (slices) before being fed into the network. This is useful in memory-limited scenarios where a small chunk is loaded, processed, and off-loaded to make room for the next. The incremental data load allows neural networks to train on large datasets without running into Out Of Memory issues.
4. Model Drift Detection
Model drift is a direct result of data drift which is gradual changes in the dataset over some time. Ackerman et.el demonstrates a technique to detect drift in models using weak data slices. Their approach analyzes largely misclassified slices of the data and detects deviations in the information.
5. Improving Model Accuracy With Slice-Based Learning
Machine learning models rarely perform equally on the entire dataset. The model performance suffers on certain subsets of data. Modern approaches use slice-based learning to train models to perform better on weak slices. The approach creates a slice function that identifies critical data subsets and trains the model to give them higher weightage. The model is further used in conjunction with attention blocks aware of these critical slices.
6. Model Validation & Fairness
To assess the uniformity of a model, ML practitioners use a technique called k-fold cross-validation. The dataset is divided into k slices, one used for validation and the remaining for training. After the training, a different slice is chosen for validation and training and this continues until all slices are validated. This approach confirms whether the trained model performs equally on all data slices.
Moreover, a model's fairness is assessed by testing it on different data slices. Data is sliced according to critical information such as race. The different slices contain data for a particular race only. Testing this way assures the practitioner that the model does not display any bias.
Slicing Computer Vision Datasets
Computer vision datasets consist of images; although the overall concept remains the same, these are handled slightly differently. Unlike traditional data, each image is loaded as a 2-Dimensional or 3-Dimensional (RGB) matrix.
The multidimensional nature of CV datasets brings in new handling and slicing challenges. These datasets are sliced along their first dimension, i.e., if we have greyscale images (2-dimensional), the dataset shape will look 200x380x380. With these dimensions, we have 200 images of shapes 380x380. The slicing operation usually works across the first dimension (200) since we want to keep individual images intact and segregate a portion.
For RGB (3-dimensional), a new dimension is added (200x3x380x380) representing the color channels, but the slicing is still done across the first dimension.
 Computer vision dataset slicing
**Source: Pytorch Community
Computer vision dataset slicing
**Source: Pytorch Community
However, for techniques like Slicing Aided Hyper Inference, slicing is also performed on individual images for augmentation purposes.
SAHI: Image Slicing for Small Object Detection
Conventional object detection models like YOLO often struggle to perform on small objects like people in a crowded space. The Slice Aided Hyper Inference technique uses sliced images (augmented) to fine-tune existing models to improve their performance on small objects in high-resolution images. The sliced images are also used during inference as object detection is performed on each slice.
 Computer vision dataset slicing
**Source: Slice-Aided Hyper Inference
Computer vision dataset slicing
**Source: Slice-Aided Hyper Inference
Automated Data Slicing
Manually figuring out data slices can be challenging, especially if the dataset is large. Tools like Slice Finder use statistical techniques to single out data subsets that may be interesting. The system takes the training data, a model, and an effect size threshold as input and uses statistical techniques to find the top-K largest problematic slices. The effect size threshold (K) can be varied to change the number of data slices for detailed experimentation
Leverage Picsellia Computer Vision Platform To Streamline Data Operations
Dataset slicing divides data into multiple parts and is vital to the data exploration routine and model training. It offers several benefits to ML practitioners, including model evaluation, data and model drift detection, and data analysis.
Computer Vision datasets are slightly challenging due to their space complexity and multidimensional nature. These can be sliced across the last dimension to create partitions between the images, or the images themselves can be cropped for augmentation. The former technique helps with dataset handling and model evaluation, while the latter helps improve performance.
Picsellia provides a convenient data management platform to handle unstructured files like images and videos. It offers an integrated annotation tool and a data version control for all your machine learning needs. To learn more, book your demo today.
Related from Picsellia
Organize and version your datasets
Version, slice, and manage datasets with full traceability — from raw images to production-ready splits.
Explore Dataset ManagementAnnotate faster with AI assistance
Picsellia's labeling tool supports bounding boxes, polygons, and segmentation masks with built-in AI assistance to speed up annotation.
Explore the Labeling ToolStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles
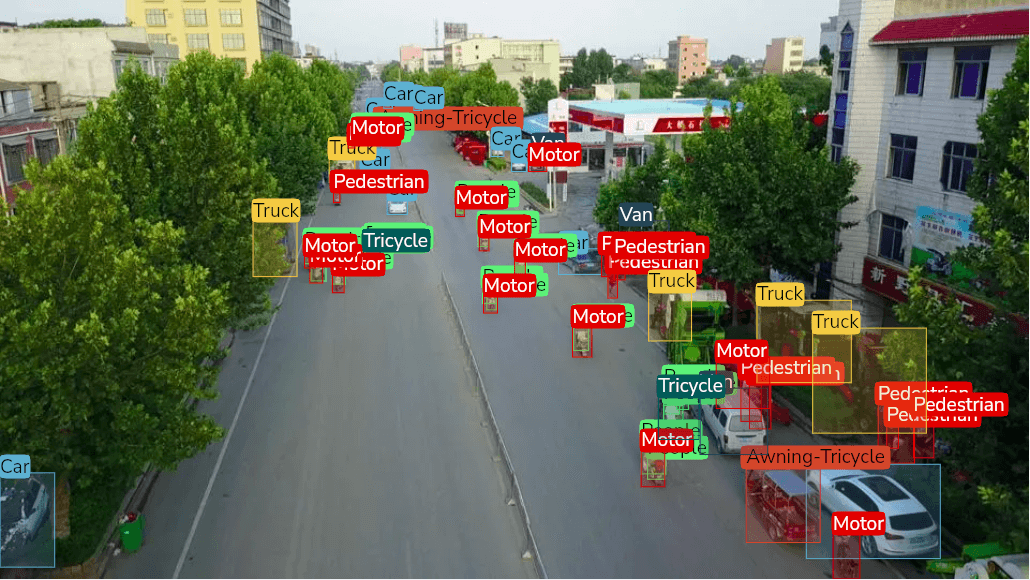
Best object detection datasets in 2024
Looking to train your object detection models? Discover a wide variety of high-quality object detection datasets to fuel your AI projects.
Data-Centric AI: A Guide to Improving ML Performance Through Data
Learn how the benefits of Data-Centric AI, a new paradigm focusing on improving data quality applies to computer vision.

How to Deal with Imbalanced Datasets in Computer Vision
Imbalanced datasets lead to problems with accuracy, overfitting, and bias. Data augmentation, class weighting and hierarchical classification can help.