Data-Centric AI: A Guide to Improving ML Performance Through Data
Learn how the benefits of Data-Centric AI, a new paradigm focusing on improving data quality applies to computer vision.
Picsellia Team
·15 min read
Organize your visual data today
Version datasets, manage annotations, and track lineage from one place.
Data is the new oil, and how we refine this oil is the new science!
Data-Centric AI is a new paradigm for data science and machine learning.
In this article we explore what data-centric AI is, how you can implement a data-centric approach to computer vision, and explore its advantages through a computer vision coding example.
What is Data-Centric AI ?
Data-Centric AI, a term coined by the infamous Andrew Ng, is one of the latest trends in the machine learning world. Data-centric AI is a wide topic but, for this article, we will focus our lens on computer vision.
For those readers who might be interested in knowing more about data-centric AI, we will provide a list of useful resources at the end of this article.
AI systems run both on code and data. “All that progress in algorithms means it's actually time to spend more time on the data,” Andrew Ng said at the recent EmTech Digital conference hosted by MIT Technology Review.
Data-centric AI is the discipline of systematically engineering the data needed to build successful AI systems.
Usually, training datasets are treated as something stationary. Once a training dataset is formed and passes through ETL, it usually remains frozen and used as it is throughout multiple projects. After that, most of the emphasis is placed on training the “best” model possible.
The data-centric approach challenges this paradigm by bringing data to the focus of attention and handling datasets as a first-class citizen in ML. Datasets gain a place in the machine learning feedback loop and methodologies that increase the performance and generalizability of a model through data are considered more important than fine-tuning a model’s parameters.
Cleaning, curating, and augmenting data to make datasets more representative of reality are the main pillars of a data-centric approach.
Data-Centric vs Model-Centric AI
Model-Centric AI focuses on:
- Model selection: which algorithm to use
- Model architecture: how many layers in a CNN, how many attention heads in a Visual Transformer
- Feature engineering: creating/selecting features
- Hyperparameter tuning: Finding the optimal set of hyperparameters for a model.
Data-Centric AI focuses on:
- Cleaning datasets: deleting duplicates, picking the most suitable frames from a video.
- Curating datasets: discovering labeling mistakes, including edge cases.
- Fixing bias: including more examples of underrepresented cases, deleting “unethical” examples.
- Augmenting training datasets: using synthetic data, mimicking the deployment scenario (e.g. adding snow on images).
- Fix labeling mistakes.
- Defining a systematic approach to data annotation.
- Curating data for test datasets: creating benchmarks representative of the deployment environment.
**Data-centric challenges in computer vision **
Labels are imperfect
We are used to thinking of labels as the ultimate “ground truth”. Our models must be able to learn these labels and propagate their knowledge to new unseen datasets.
However, many interesting studies [1, 2, 3] have proved that even the most popular computer vision dataset benchmarks contain a lot of mistakes!
Sometimes, these mistakes are accidental, whereas other times human experts are not able to agree on their labeling.
 Data centric ai a guide to improving ml performance through data
*Fig. 1: Examples of incorrect labels in various image datasets found and corrected using cleanlab. *
Data centric ai a guide to improving ml performance through data
*Fig. 1: Examples of incorrect labels in various image datasets found and corrected using cleanlab. *
Things get increasingly complicated for more advanced computer vision applications such as object detection and image segmentation. Not only do we find classification errors, but bounding box and pixel annotations can be inaccurate, inconsistent, or noisy. Setting up systematic ways for data annotation is essential for ensuring high-quality computer vision datasets.
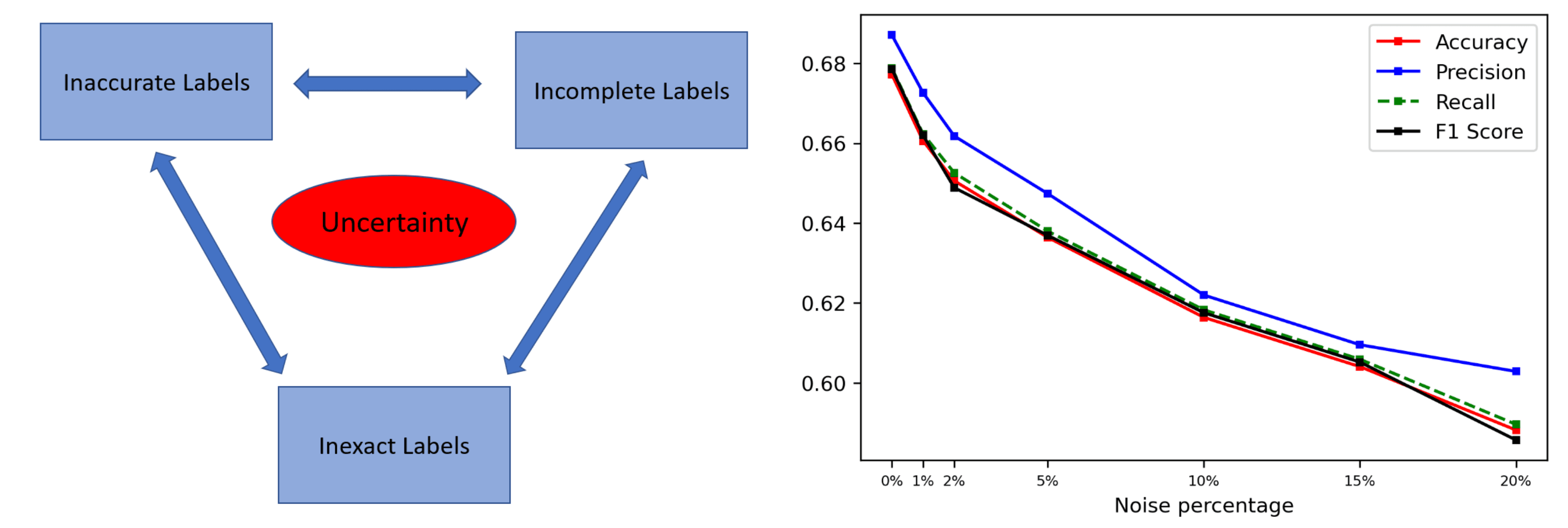
This combination of inexact, incomplete, and inaccurate labeling diminishes the quality of the supervisory signal in labeled datasets. Uncertainty forms inside the dataset, which naturally propagates into the model’s predictions.
 Data centric ai a guide to improving ml performance through data
Fig.2: Mistakes and imperfections in the training dataset create uncertainty which inevitably propagates into the model and its predictions.
Data centric ai a guide to improving ml performance through data
Fig.2: Mistakes and imperfections in the training dataset create uncertainty which inevitably propagates into the model and its predictions.
Real World Datasets are imperfect
Training datasets are incomplete and finite. Our datasets are finite but real-world scenarios are not. There is only so much you can capture with a single training dataset.
To add to the complexity, data shifts and domain shifts are also big issues. A self-driving car is trained on a US city with a warm climate. The algorithm may behave very well inside the domain it was trained on. However, snowy weather conditions may severely degrade its performance, this is a form of data shift. Moreover, the same algorithm is undoubtedly not going to make it very far in overpopulated Asian cities during rush hours.
Why do I need a Data-Centric approach?
Nowadays, there is a vast availability of pre-trained machine learning and deep learning models. Both the two major deep learning frameworks - TensorFlow and PyTorch - offer off-the-shelve pre-trained models through their model hubs, which you can use for inference in just a few lines of code. Not to mention the sheer number of Transformer models readily available through Hugging Face.
Moreover, an increasing number of researchers open source their models on GitHub. A quick look at papers with code will help you discover the right repository for multiple computer vision fields be it 3D object detection, self-supervised semantic segmentation, or generative image models.
With such a vast availability of pre-trained models, not every organization needs to develop computer vision models from scratch. We should aim at leveraging what has already been developed by the community, then tune and refine models to make them serve the use case of our business.
Data-centric AI puts the focus on improving the fuel deep learning models run on: the data.
**Data-centric AI advantages **
- Minimal time is allocated developing & training new models. Such development is often a reinvention of the wheel.
- Every model eventually becomes outdated. Improving the training data is a model-agnostic method, though.
- Less technical debt accumulation is created and less maintenance is required when working with readily available models.
- Methodologies that improve data quality can be transferable across models, projects, and organizations.
- Model bias, data privacy, and AI ethics are usually only solved through the ‘data highway’ and not by refining the model itself.
- Curating and correcting test datasets (benchmarks) allow for a more realistic performance evaluation after deployment.
How to improve data quality in computer vision
Here is a non-exhaustive list of tips to improve data quality:
- Visualize, explore, and always be vigilant about mistakes on your training and testing datasets.
- Explore data-centric tools to improve your datasets.
- Set up robust data pipelines.
- Implement pipeline testing to catch errors during data processing.
- Define labeling and strict annotation rules to be followed and reduce inconsistency.
- Often inspect your models for possible biases. This will guide your dataset updates.
When you suspect your evaluation datasets contain noisy labels consider the following:
-
Correct your test labels. Techniques like confident learning [2] (cleanlab** tool) can help you discover mistakes. This helps because:**
-
you evaluate the validity of your benchmarks;
-
performance on corrected test sets is more representative of reality, so you avoid unpleasant surprises during deployment [1].
-
Be extra careful about overfitting. It’s possible to “increase” test set performance just by overfitting on a test set’s noise rather than the actual signal.
-
Consider using smaller models. [1, 2] found that ResNet18 outperforms ResNet50 if 6% noise is added to the ImageNet test set. This is not surprising considering that larger models overfit noisy features more.
-
Your datasets may be much noisier than these highly curated benchmark datasets.
**Code Experiments **
We’ve run some data-centric experiments for you. Theory is good but machine learning is a highly practical field so let’s get our hands dirty!
For our experiments, we will use the common CIFAR-10 dataset. It’s a very popular dataset with thousands of citations. I also explored its curated test-set version published here.
A meta-annotation with Mechanical Turk annotators found only 7 mistakes. So we can consider it a very well-curated dataset.
Model-wise, I use a typical MobileNetV2 pre-trained on ImageNet with a 10-class classification layer on top. The model has about 2.2M trainable parameters. MovileNetV2 is considered a lightweight model that achieves medium to high accuracy on most typical computer vision benchmark datasets.
The model remains static throughout the experiments. The training parameters also remain frozen. I train for a maximum of 100 epochs using early stopping monitored on val_loss (patience=5), with adam optimizer, typical 1e-4 learning rate with decay (patience=2), and a batch size of 180. An overall pretty standard setup.
The only changes I am allowed to make are data-related, e.g. include more data, delete data, infuse label noise, include augmentation techniques, etc.
Baseline Performance
In my first experiment I set the baseline performance using only 50% of the available data.
Following on, you will see the effects of increasing the training data!
The baseline training dataset is very well-balanced. Class frequency lies around 10% for each of the 10 classes.
 Data centric ai a guide to improving ml performance through data
Fig. 3: Loading the baseline dataset, using only 50% of the available CIFAR-10 training samples.
Data centric ai a guide to improving ml performance through data
Fig. 3: Loading the baseline dataset, using only 50% of the available CIFAR-10 training samples.
 Data centric ai a guide to improving ml performance through data
*Fig. 4: Class frequency distribution of our baseline training dataset with 20K samples. *
Data centric ai a guide to improving ml performance through data
*Fig. 4: Class frequency distribution of our baseline training dataset with 20K samples. *
1. We train the model on the above dataset. The training curves don’t show any serious abnormalities, except for a rather large gap between train-val sets.
 Data centric ai a guide to improving ml performance through data
Data centric ai a guide to improving ml performance through data
 Data centric ai a guide to improving ml performance through data
Fig. 5: Learning curves of the baseline model.
Data centric ai a guide to improving ml performance through data
Fig. 5: Learning curves of the baseline model.
2. We evaluate the model’s performance on the validation dataset. Overall we get a medium-to-high performance, with open room for improvement.
The network seems to mostly struggle with classifying correctly classes 2, 3, 4, and 5, namely ‘birds’, ‘cats’, ‘deers’, and our best friends ‘dogs’.
 Data centric ai a guide to improving ml performance through data
Fig. 6: Baseline model’s results on the validation dataset.
Data centric ai a guide to improving ml performance through data
Fig. 6: Baseline model’s results on the validation dataset.
- Plotting the confusion matrix gives us more information about potential biases and common mistakes.
- We observe a bias towards class 4, the lovely
deers. Many misclassifications target class 4. Similar problems arise for classes 2,3 and 7. - There is high confusion between classes 3 and 5, the eternal ‘cats’ vs ‘dogs’ war. A similar pattern also arises for classes 0 (‘airplane’) and 1 (‘automobile’).
 Data centric ai a guide to improving ml performance through data
Fig. 7: Baseline model’s confusion matrix on the baseline validation dataset.
Data centric ai a guide to improving ml performance through data
Fig. 7: Baseline model’s confusion matrix on the baseline validation dataset.
**The Effects of Quality Data - Training with Noisy Labels **
We all know the quote, “Garbage in, garbage out”. Let’s see if it really holds!
I deliberately infest the training labels in our baseline dataset with noise, randomly changing the label of a sample.
Bear in mind we change nothing in the validation and test sets. The figures below show how many mistakes we introduced to each class.
 Data centric ai a guide to improving ml performance through data
Data centric ai a guide to improving ml performance through data
 Data centric ai a guide to improving ml performance through data
Fig. 8: Frequency of errors deliberately infused in the training dataset. The left figure applies to 1% error noise while the right figure applies to 10% error noise. The x-axis denotes the class id while the y-axis denotes the error frequency.
Data centric ai a guide to improving ml performance through data
Fig. 8: Frequency of errors deliberately infused in the training dataset. The left figure applies to 1% error noise while the right figure applies to 10% error noise. The x-axis denotes the class id while the y-axis denotes the error frequency.
Despite the changes, the overall class distribution still remains balanced. Since errors are introduced randomly with homogeneous probability, we don’t expect any strong imbalance.** **
** **
 Data centric ai a guide to improving ml performance through data
Fig. 9: Class distribution of the noisy training dataset (10% label noise).
Data centric ai a guide to improving ml performance through data
Fig. 9: Class distribution of the noisy training dataset (10% label noise).
**Noise in the training dataset’s labels severely disrupts a machine learning model’s performance. **From our experiments, we observe that introducing just 1% noise in the training labels degrades validation performance by almost 2%. The validation performance decrease ranges from 2% to 10%. It’s interesting to note that the slope of the curve is not constant.
 Data centric ai a guide to improving ml performance through data
Data centric ai a guide to improving ml performance through data
Fig. 10: Performance on the **validation **set when training labels contain noise.
We can see a similar effect present in the test-set performance. The effects of label noise are more than obvious with performance dropping from 1% to almost 10%. Notice how drastic test-set performance degradation is when label noise increases from 1% to 2%!
 Data centric ai a guide to improving ml performance through data
*Fig. 11: Performance on the **test *set when training labels contain noise.
Data centric ai a guide to improving ml performance through data
*Fig. 11: Performance on the **test *set when training labels contain noise.
**Improvement Idea 1 - Data Augmentation **
The first data-centric improvement that comes to mind is to use data augmentation methods. Keeping the model and training params frozen, I include some augmentation layers before feeding the inputs. Mind that training and validation sets remain exactly the same.
The network definitely has trouble overfitting the training data now. No visible improvement, however, despite the extra training costs due to the augmentation overhead. To avoid the augmentation overhead you may want to create augmented datasets and store them on disk instead of doing augmentation on the fly.
 Data centric ai a guide to improving ml performance through data
Data centric ai a guide to improving ml performance through data
 Data centric ai a guide to improving ml performance through data
Data centric ai a guide to improving ml performance through data
 Data centric ai a guide to improving ml performance through data
Fig. 12: Performance after using augmentation methods.
Data centric ai a guide to improving ml performance through data
Fig. 12: Performance after using augmentation methods.
In our case, the augmentations we applied did not provide any benefits. It’s possible that different augmentation parameters may provide more favorable results. However, finding an optimal combination requires fine-tuning the augmentation parameters.
Adjusting augmentations to your deployment scenario is essential for success!
 Data centric ai a guide to improving ml performance through data
Fig. 13: Confusion matrix for the augmentation model. No benefit was achieved.
Data centric ai a guide to improving ml performance through data
Fig. 13: Confusion matrix for the augmentation model. No benefit was achieved.
Improvement Idea 2 - Gather more specific data
From the baseline model, we saw that the model often confused ‘cats’ and ‘dogs’. My thought was that providing more samples from these two confusing classes could possibly help the network draw better boundaries.
So I decided to create an artificially biased dataset and enhance it by including 1000 more specific examples from each of the two classes.
 Data centric ai a guide to improving ml performance through data
* Fig. 14: An artificially “biased” dataset created by sampling more ‘cats’ and ‘dogs’ examples. *
Data centric ai a guide to improving ml performance through data
* Fig. 14: An artificially “biased” dataset created by sampling more ‘cats’ and ‘dogs’ examples. *
The network’s performance has not shown any particular improvements, probably the opposite. To my surprise, the two classes were actually negatively affected!
Not only the confusion didn’t improve but the overall performance dropped.
To my huge surprise, the two classes were actually negatively affected!
 Data centric ai a guide to improving ml performance through data
* Fig. 15: Performance on the “biased” dataset.*
Data centric ai a guide to improving ml performance through data
* Fig. 15: Performance on the “biased” dataset.*
The confusion between cats and dogs hasn’t been corrected and misclassification targeting ‘deers’ worsened. Unbalancing the dataset created more problems than it solved. I would call it ‘back to square one’.
 Data centric ai a guide to improving ml performance through data
Fig. 16: Confusion matrix of the “biased” dataset.
Data centric ai a guide to improving ml performance through data
Fig. 16: Confusion matrix of the “biased” dataset.
The Effects of Big Data - Training with more Data
Can we increase our model’s performance just by using more data? I would expect so, but as with many other things in deep learning, you can’t really know it until you test it.
I trained the same exact setup while incrementally increasing my training dataset’s size. The results are summarized in the graph below. As we expected, the more data we use, the higher the performance, reaching about 81% F1 score and 80% accuracy when using the full clean dataset.
Overall, we got about a 13% increase in our metrics by doubling the training dataset’s size.
 Data centric ai a guide to improving ml performance through data
Fig. 17: Performance improvements gained by increasing the training dataset size.
Data centric ai a guide to improving ml performance through data
Fig. 17: Performance improvements gained by increasing the training dataset size.
Conclusions
From the above experiments we saw that boosting a dataset’s size can greatly increase performance. However, gathering more data is often expensive, time-consuming, and even impossible in some real-world scenarios!
Instead, you can make sure your existing dataset is clean of label errors and follows consistent annotation principles. Increasing the quality of data can massively improve performance, especially if a dataset is already of low quality.
Final thoughts on Data-Centric AI
Data-centric machine learning is a promising new avenue for organizations. Focusing on improving data quality, dataset size, and relevancy can greatly impact your models’ performance. Data-centric approaches can possibly help you combat data biases and data drifts more effectively, making your production models more robust.
“Data-Centric AI vs Model Centric AI” is a common debate. However, the two paradigms are not mutually exclusive and can coexist. Nowadays, we are lucky to have easy access to some of the most amazing machine learning models ever created. This gives us more time to devote to improving our data pipelines and operations. Once you spend enough time curating your datasets then it makes sense to actually focus on fine-tuning your deep learning model.
Paraphrasing the words of Andrew Ng, the pioneer of data-centric AI,
*“Instead of ****only ***focusing on the code, companies should focus on developing systematic engineering practices for improving data in ways that are reliable, efficient, and systematic.”
References
- Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
- Confident Learning: Estimating Uncertainty in Datase Labels
- Learning with Confident Examples: Rank Pruning for Robust Classification with Noisy Labels
- https://datacentricai.org/
- https://datacentricai.community/
- A large collection of data-centric AI resources
Related from Picsellia
Organize and version your datasets
Version, slice, and manage datasets with full traceability — from raw images to production-ready splits.
Explore Dataset ManagementAnnotate faster with AI assistance
Picsellia's labeling tool supports bounding boxes, polygons, and segmentation masks with built-in AI assistance to speed up annotation.
Explore the Labeling ToolStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles

Computer Vision Dataset Slicing
Discover dataset slicing, a technique used to divide large datasets into smaller parts to train and test models and improve model accuracy.
Best object detection datasets in 2024
Looking to train your object detection models? Discover a wide variety of high-quality object detection datasets to fuel your AI projects.

How to Deal with Imbalanced Datasets in Computer Vision
Imbalanced datasets lead to problems with accuracy, overfitting, and bias. Data augmentation, class weighting and hierarchical classification can help.