Activation Functions and Neural Networks
Explore the key roles of activation functions in neural networks for computer vision tasks. Learn about Sigmoid, ReLU, and more for better deep learning.
Picsellia Team
·9 min read
Ship models faster
Track experiments, compare runs, and iterate faster with built-in tooling.
Introduction
Let's say we want to predict the finalists of the Rugby World Cup. Instead of relying solely on human analysis, we can use a Deep Learning model.
The model would be trained on historical data of Rugby World Cup matches, including team performances and outcomes. By applying successive transformations to the input data using activation functions, the model learns complex patterns and relationships.
Once trained, the model takes in the recent performances of participating teams as input. It uses activation functions to process the data and make predictions about the two teams most likely to reach the finals.
This article aims to explore various activation functions commonly employed in computer vision tasks. We will delve into their properties, discuss advantages and limitations, and provide specific examples to illustrate their applications in different scenarios.
Understanding Neural Networks
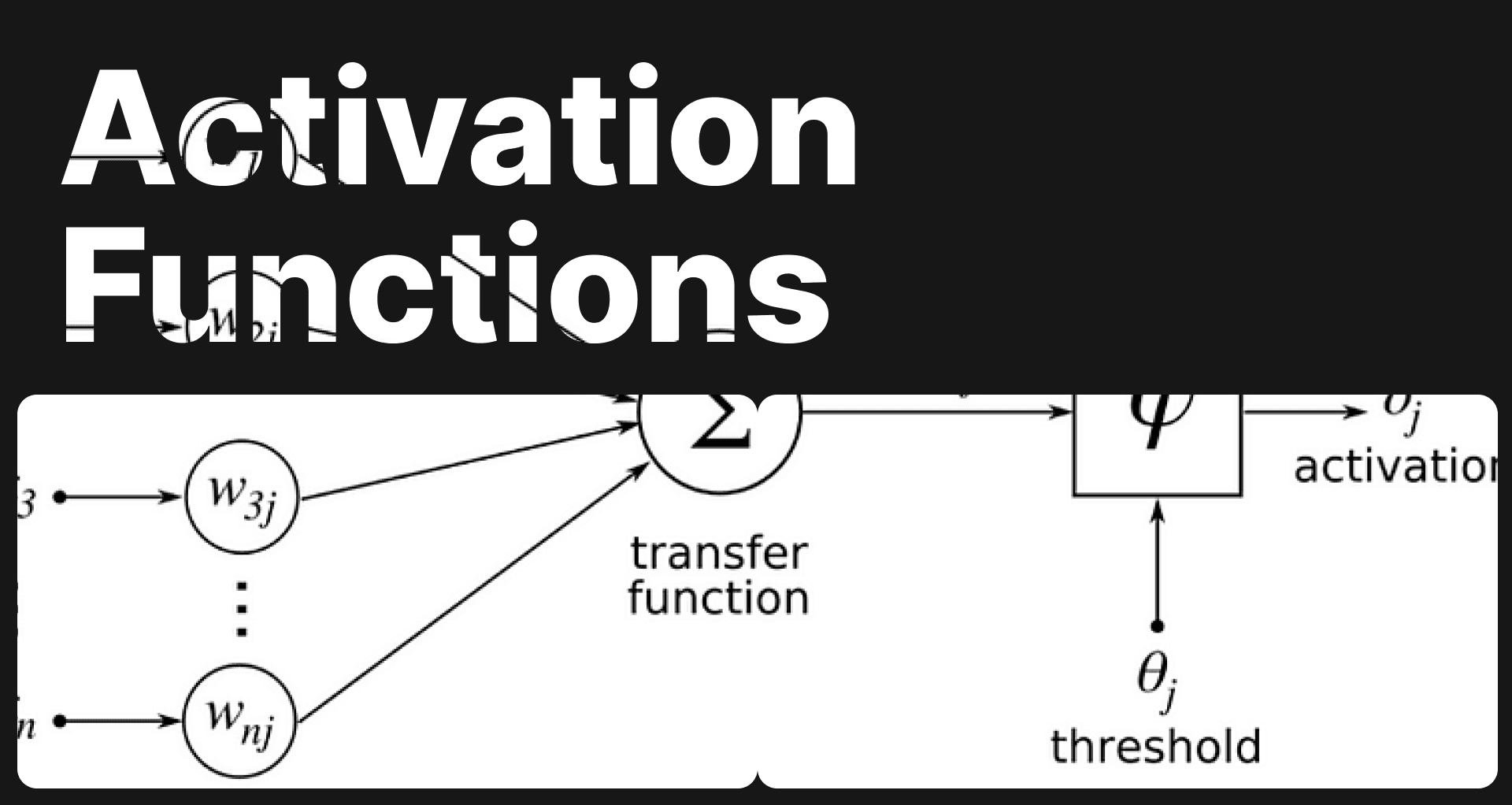
Before we dive into the intricacies of activation functions, let's briefly recap the concept of neural networks in computer vision. Neural networks, inspired by the complexity of the human brain, consist of interconnected layers of artificial neurons. There is an input and output layer, linked by hidden layers as shown on the figure. Each hidden layer is made with neurons connected to one or several neurons from the previous and following layer. Neurons are actually function.
 Activation functions and neural networks
https://www.tibco.com/
Activation functions and neural networks
https://www.tibco.com/
To simplify: if we look at the input data as a starting point and the output data as an end point, we can see the neural network as a combination of the paths that the input data takes to arrive at the result.
Through the training process, these networks learn to recognize patterns and make predictions by adjusting the weights and biases of these neurons.
The Weights
Weights represent the coefficients within a neural network's equation. When training a neural network using a training dataset, it begins with a predetermined set of weights. These weights are subsequently adjusted and optimized during the training process to achieve the best possible values.
It happens during the training process through a technique called backpropagation combined with gradient descent.
- Initialization: The first step consists in randomly initializing the weights, each weight representing a parameter that determines the influence of a particular feature or filter in the network.
- Forward Propagation: During forward propagation, input data is fed into the network, and the weights are used to compute the output predictions. The predictions are then compared to the actual labels to calculate the loss, which represents the discrepancy between the predicted and actual values.
- Backpropagation: In this step, the gradients of the loss with respect to the weights are computed using the chain rule of calculus. The gradients indicate the direction and magnitude of the weight adjustments needed to reduce the loss.
- Gradient Descent: The computed gradients are used to update the weights in the network. Gradient descent is employed, which involves taking small steps in the direction opposite to the gradients, aiming to minimize the loss. The learning rate determines the size of these steps.
- Iterative Optimization: Steps 2-4 are repeated iteratively over the training dataset. Each iteration is known as an epoch. As the training progresses, the network gradually learns to adjust its weights to reduce the loss and improve the accuracy of its predictions.
- **Convergence: **The training process continues until a stopping criterion is met, such as reaching a maximum number of epochs or observing a negligible improvement in performance.
By repeatedly adjusting the weights based on the computed gradients, the CNN learns to recognize meaningful patterns and features in the input data, optimizing the weights to achieve the best possible values for accurate predictions.
The Bias
Bias, on the other hand, is a fixed value that is added to the product of inputs and weights. It serves as the opposite of the threshold, determining when to activate the activation function. In essence, the bias value governs the decision-making process of the activation function.
 Activation functions and neural networks
Activation functions and neural networks
Activation functions play a pivotal role in this process, acting as nonlinear transformations applied to the outputs of these neurons, enabling them to model complex relationships between inputs and outputs.
Importance of Activation Functions in Neural Networks
Neural networks without activation functions would be limited to representing linear transformations, rendering them inadequate for solving complex problems. Activation functions introduce nonlinearity, enabling neural networks to capture intricate patterns and make more accurate predictions. By applying a suitable activation function, the network's expressive power increases exponentially, allowing it to learn and generalize from complex datasets.
 Activation functions and neural networks
https://studymachinelearning.com
Activation functions and neural networks
https://studymachinelearning.com
Popular Activation Functions
In this section, we will explore several popular activation functions used extensively in computer vision tasks and analyze their characteristics, advantages, and limitations.
- Sigmoid Activation Function
The sigmoid activation function, also known as the logistic function, is a classic choice in neural networks.
 Activation functions and neural networks
https://insideaiml.com
Activation functions and neural networks
https://insideaiml.com
- Definition and properties :
The sigmoid function maps the input to a range between 0 and 1.
-
Suitable for binary classification tasks. It has a smooth S-shaped curve, facilitating smooth gradient-based optimization.
-
Use Cases and Limitations in Computer Vision: While sigmoid was widely used in the past, it has limitations, such as the vanishing gradient problem. As the input becomes extremely large or small, the gradient approaches zero, leading to slower convergence and challenges in training deep neural networks.
-
Rectified Linear Unit (ReLU)
ReLU has gained significant popularity in recent years, particularly for its simplicity and effectiveness in deep neural networks.
 Activation functions and neural networks
https://www.nomidl.com
Activation functions and neural networks
https://www.nomidl.com
- Definition and Properties:
 Activation functions and neural networks
Activation functions and neural networks
The ReLU activation function returns the input as is if positive, and zero otherwise. It introduces sparsity and computational efficiency by zeroing out negative values.
-
Advantages over Sigmoid Activation Function: ReLU overcomes the vanishing gradient problem associated with the sigmoid function, enabling faster convergence and more effective training of deep neural networks.
-
Application Examples: In computer vision tasks like object detection and segmentation, ReLU activation functions have proven highly successful due to their ability to handle large-scale datasets and capture complex features.
-
Leaky ReLU
Leaky ReLU addresses the "dying ReLU" problem encountered with regular ReLU, where some neurons become inactive.
 Activation functions and neural networks
https://www.i2tutorials.com
Activation functions and neural networks
https://www.i2tutorials.com
- Definition and Properties: Leaky ReLU introduces a small slope for negative inputs, allowing a small gradient to flow even for negative values, thus preventing neurons from dying.
 Activation functions and neural networks
Activation functions and neural networks
-
Addressing the "Dying ReLU" Problem: By mitigating the problem of dead neurons, Leaky ReLU ensures that the network retains its capacity to learn and generalize effectively.
-
Use Cases and Benefits in Computer Vision: Leaky ReLU finds applications in various computer vision tasks, such as image classification, where the prevention of dead neurons contributes to the network's overall performance.
-
Hyperbolic Tangent (tanh)
The hyperbolic tangent function shares similarities with the sigmoid function but offers a slightly different range of output values.
 Activation functions and neural networks
https://www.ml-science.com
Activation functions and neural networks
https://www.ml-science.com
- Definition and Properties:
 Activation functions and neural networks
Activation functions and neural networks
Tanh maps the input to a range between -1 and 1, exhibiting similar properties to the sigmoid function but with a steeper gradient around zero.
-
Comparisons to Sigmoid and ReLU Activation Functions: tanh avoids the saturation issue associated with sigmoid by providing symmetry around zero. However, similar to sigmoid, tanh can suffer from the vanishing gradient problem.
-
Application Examples: tanh finds application in computer vision tasks requiring outputs within a specific range, such as facial expression recognition or gesture recognition.
-
Softmax
Softmax is particularly useful in multi-class classification problems, providing probability distribution across multiple output classes.
- Definition and Properties:
 Activation functions and neural networks
Activation functions and neural networks
Softmax normalizes the outputs of a neural network layer, ensuring they sum up to one, allowing interpretation as class probabilities.
- Role in Multi-class Classification Problems: Softmax is commonly used in computer vision tasks like image categorization, where the network must assign a single label to the input image from multiple possible classes.
- Usage and Benefits in Computer Vision: Softmax enables confident predictions by producing class probabilities, aiding in decision-making for various computer vision applications.
Choosing the Right Activation Function
Selecting the appropriate activation function for a given computer vision task is crucial for achieving optimal results. Several factors should be considered during this selection process.
1. Task Requirements and Data Characteristics: Different computer vision tasks require specific activation functions. Understanding the requirements of the task, such as binary or multi-class classification, object detection, or segmentation, helps guide the choice of activation function.
2. Performance and Convergence Speed: Activation functions can significantly impact the speed of convergence and overall performance of the neural network. Some functions facilitate faster convergence, while others might slow it down. It is important to evaluate the trade-offs and select accordingly.
3. Avoiding Vanishing and Exploding Gradients: Vanishing and exploding gradients can impede the training process. Careful selection of activation functions can help alleviate these issues and promote stable and efficient training.
Activation Function Selection for Specific Computer Vision Tasks
Different computer vision tasks have varying requirements, and choosing the right activation function is critical for achieving optimal performance. Let's explore the recommended choices for some common computer vision tasks:
1. Image Classification: ReLU and its variants, such as Leaky ReLU, are commonly used in image classification due to their ability to capture complex features efficiently. Additionally, softmax is applied in the final layer to obtain class probabilities.
2. Object Detection: Object detection tasks often benefit from the usage of activation functions like ReLU, which handle large-scale datasets and complex feature extraction. Softmax may also be used for classifying detected objects.
3. Semantic Segmentation: Semantic segmentation requires precise boundary detection, making activation functions like ReLU and Leaky ReLU popular choices. These functions facilitate the network's ability to capture intricate object boundaries and generate accurate segmentation maps.
Conclusion
Activation functions are fundamental components of neural networks, especially in computer vision tasks. We explored various popular activation functions, their properties, advantages, and limitations. The appropriate choice of activation function can significantly impact the performance, convergence speed, and generalization capabilities of the network. Moreover, advanced activation functions and techniques offer exciting possibilities for further improving the effectiveness of neural networks in computer vision.
Related from Picsellia
Track every experiment
Log metrics, parameters, and artifacts automatically. Compare runs side by side and ship better models faster.
See Experiment TrackingShip vision AI 10x faster
Picsellia is the end-to-end MLOps platform for computer vision — from data management to production deployment.
See the PlatformStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles
Mask R-CNN - Everything explained
Explore Mask R-CNN: a groundbreaking tool in computer vision for object detection & instance segmentation. Dive deep into its architecture & applications.

Understanding Overfitting in Machine Learning
Learn to tackle overfitting in machine learning with effective strategies and Picsellia's MLops platform. Avoid model memorization.

Understanding the F1 Score in Machine Learning: The Harmonic Mean of Precision and Recall
In this article, we will delve into the concept of the F1 score, its relationship with precision and recall, andwhy it is advantageous to use the F1 score.