Mask R-CNN - Everything explained
Explore Mask R-CNN: a groundbreaking tool in computer vision for object detection & instance segmentation. Dive deep into its architecture & applications.
Picsellia Team
·8 min read
Ship models faster
Track experiments, compare runs, and iterate faster with built-in tooling.
In computer vision, different tasks exists as introduced in our previous blogpost Segmentation vs Detection vs Classification in Computer Vision: A Comparative Analysis. As explained in the article, there are two types of segmentation, semantic segmentation and instance segmentation. In this article we will discover one of the most powerful archtecture for instance segmentation, which is Mask R-CNN.
Understanding Instance Segmentation
Instance segmentation goes beyond traditional image classification and object detection by providing a pixel-level understanding of objects within an image.
Instance segmentation is actually a combination of two sub problems: object detection and semantic segmentation. It aims to differentiate individual instances of objects and outline their boundaries accurately. The bounding box is created from image detection and shaded masks are the output of semantic segementtion.
This level of granularity opens up a wide range of applications, from object counting and tracking to understanding object shapes and interactions.
 Mask r cnn everything explained
Example of instance segmentation : https://blog.paperspace.com/
Mask r cnn everything explained
Example of instance segmentation : https://blog.paperspace.com/
An Overview of Mask R-CNN’s history
Introduced in 2014, R-CNN, Regions with Convolutional Neural Networks, was one of the first approaches to use Convolutional Neural Networks for object detection. R-CNN operates in three steps:
- Generating region proposals
- Extracting features from these regions using pre-trained CNNs
- Classifying the regions and adjusting bounding boxes.
However, because of the independent processing of proposed regions, R-CNN was slow but still promising.
It gave birth one year later to an improved version called **Fast R-CNN, which **significantly sped up the object detection process compared to R-CNN. Indeed, instead of independently classify each region, it used a single convolutional network to extract features from the entire image.
The same year, in 2015, Faster R-CNN is proposed, it introduced the concept of the Region Proposal Network (RPN). The RPN shares CNN features with the object detector to automatically generate potential Regions of Interest (RoI). This approach further accelerates the process of region proposal generation and improves object detection performance.
In 2017, Mask R-CNN, which extends the success of Faster R-CNN to instance segmentation is presented. Mask R-CNN incorporates a Mask Head into the Faster R-CNN architecture to generate pixel-level segmentation masks for each detected object. This approach enables both object detection and instance segmentation to be performed in a single network. Mask R-CNN is widely recognized for its outstanding performance in object detection and instance segmentation.
Since the introduction of Mask R-CNN, many improvements and variants have been proposed to enhance its speed and performance. Architectures like EfficientDet and Cascade Mask R-CNN have also been developed to push the boundaries of object detection and instance segmentation. However, Mask R-CNN remains one of the most influential and widely used models in the field of computer vision.
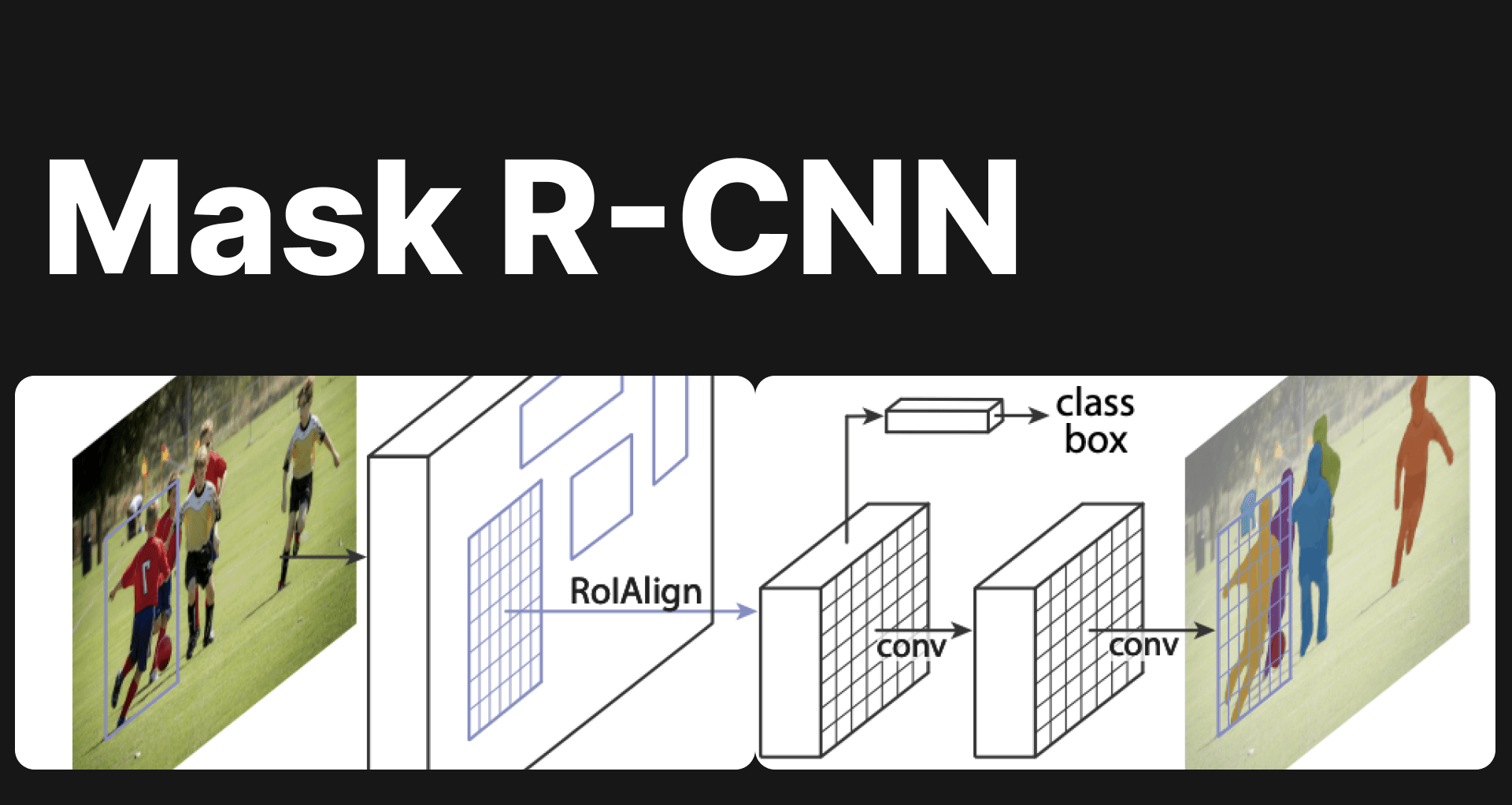
Step-by-Step Process of Mask R-CNN for Instance Segmentation
 Mask r cnn everything explained
https://ars.els-cdn.com
Mask r cnn everything explained
https://ars.els-cdn.com
Let's delve into the step-by-step process of Mask R-CNN for instance segmentation.
Step 1 : Backbone network
The backbone network is the first step of Mask R-CNN. Its role is to transform the raw image into a rich representation of its visual features by extracting relevant features from the input image. The backbone typically consists of multiple convolutional layers, pooling operations and other non-linear operations that enable capturing information from low level to high-level in the image.
Step 2: Region Proposal Network (RPN)
Thanks to the the features extract by the backbone network, the RPN scans the image and proposes potential object regions using predefined anchor boxes. These anchor boxes are of different aspect ratios and scales and act as potential bounding boxes around objects.
The RPN assigns a score to each region proposals indicating its resemblance to a real object. A high objectness score implies a likely presence of an object of interest within the proposed region, whereas a low score suggests that the region is probably background or doesn't contain any relevant object.
 Mask r cnn everything explained
First Regions proposals, https://github.com/matterport/Mask_RCNN**
Mask r cnn everything explained
First Regions proposals, https://github.com/matterport/Mask_RCNN**
Step 3: Feature Pyramid Network (FPN)
Mask R-CNN incorporates a Feature Pyramid Network to address the challenge of multi-scale feature representation. The FPN constructs a feature pyramid by merging features from different layers of a convolutional neural network. This pyramid structure provides a multi-scale representation of the image, with features levels at different spatial resolutions.
Step 4: Region of Interest (RoI) Align
Once the feature pyramid ic created by the FPN, the region proposals generated by the RPN are used to extract features from the region of interests. This is where RoI Align comes into play. Instead of using the traditional RoI Pooling operation, which can lead to issues with inaccurate alignment, Mask R-CNN utilizes RoI Align which employs bilinear interpolation to sample features from the original feature map, resulting in precise feature alignment and accurate localization of object boundaries.
Train Mask R-CNN models without the MLOps headache
Picsellia handles dataset versioning, annotation, experiment tracking, and deployment — so you can focus on building better segmentation models.
Join hundreds of CV engineers who ship models faster with Picsellia
Step 5: Classification and Bounding Box Regression
Once the region proposals are generated and aligned using RoI Align, Mask R-CNN performs classification and bounding box regression. It passes the RoI-aligned features through a shared fully connected network, which predicts the class probabilities for each proposed region. The network also regresses the coordinates of the bounding boxes to refine their positions and sizes. This step ensures accurate object classification and precise localization.
 Mask r cnn everything explained
https://github.com/matterport/Mask_RCNN
Mask r cnn everything explained
https://github.com/matterport/Mask_RCNN
Step 6 : Mask Head and Mask Prediction
The mask head network is responsible for generating pixel-level masks for each detected object region. It takes the RoI-aligned features as input and passes them through a series of convolutional layers and upsampling operations to produce the final segmentation masks. The mask prediction branch, consisting of a binary mask classifier, predicts whether each pixel belongs to the foreground (object) or background. The output is a high-resolution mask for each object instance, accurately delineating the object boundaries.
 Mask r cnn everything explained
https://www.shuffleai.blog
Mask r cnn everything explained
https://www.shuffleai.blog
Step 7 : Training and Inference
To train Mask R-CNN, a large annotated dataset is required, with pixel-level masks for each object instance. During training, the network is optimized using a combination of loss functions:
-
Classification Loss: Ensures accurate object classification by comparing predicted class probabilities with ground truth labels.
-
Bounding Box Regression Loss: Refines the predicted bounding box coordinates to match the ground truth annotations.
-
Mask Segmentation Loss: Compares the predicted instance masks with the ground truth masks to guide the network in generating accurate segmentation results.
During inference, Mask R-CNN applies the trained model to unseen images, performing region proposals, classification, bounding box regression, and mask prediction in a unified manner. The result is accurate instance segmentation, with objects distinctly outlined and labeled within the image.
 Mask r cnn everything explained
https://github.com/matterport/Mask_RCNN
Mask r cnn everything explained
https://github.com/matterport/Mask_RCNN
Performance and Applications :
The accuracy and robustness of the The R-CNN model is a valuable tool in a variety of applications, not least because of its accuracy and robustness. Accurate segmentation of instances is essential in tasks such as identifying pedestrians and objects on roads for autonomous cars, accurate segmentation of organs in medical images, object tracking, robotics and augmented reality.
However, obtaining accurate segmentation of instances poses a number of problems. Objects may have complex shapes, occlusions or overlapping boundaries, making accurate separation difficult. Variations in scale, lighting conditions and object orientation add to the complexity. Instance segmentation algorithms need to be robust and able to handle these challenges to provide reliable results.
Conclusion
Mask R-CNN represents a significant breakthrough in achieving accurate instance segmentation. By extending the Faster R-CNN framework and incorporating pixel-level segmentation, Mask R-CNN has set new standards in object detection and segmentation tasks. Its versatility, accuracy, and robustness make it a powerful tool for professionals in computer vision, from data scientists and machine learning engineers to CTOs. As computer vision continues to advance, we can expect further refinements and advancements in instance segmentation techniques, pushing the boundaries of what machines can achieve in understanding visual data.
From annotation to deployment — one platform
Picsellia gives you pixel-level annotation tools, experiment tracking, and model deployment for instance segmentation projects. Used by 100+ CV teams.
Join hundreds of CV engineers who ship models faster with Picsellia
Related from Picsellia
Track every experiment
Log metrics, parameters, and artifacts automatically. Compare runs side by side and ship better models faster.
See Experiment TrackingAutomate your ML pipelines
Set up continuous training and deployment with automated triggers, shadow deployments, and feedback loops.
Explore Automated PipelinesStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles
Activation Functions and Neural Networks
Explore the key roles of activation functions in neural networks for computer vision tasks. Learn about Sigmoid, ReLU, and more for better deep learning.

Understanding Overfitting in Machine Learning
Learn to tackle overfitting in machine learning with effective strategies and Picsellia's MLops platform. Avoid model memorization.

Understanding the F1 Score in Machine Learning: The Harmonic Mean of Precision and Recall
In this article, we will delve into the concept of the F1 score, its relationship with precision and recall, andwhy it is advantageous to use the F1 score.