What Is Image Data Augmentation?
To solve the problem of data scarcity, we use data augmentation techniques. But how do you augment image data? We'll go throw this in a simple way.
Picsellia Team
·6 min read

Organize your visual data today
Version datasets, manage annotations, and track lineage from one place.
You had a groundbreaking idea for a machine learning (ML) project and found a great dataset online. You train this data using state-of-the-art ML techniques and produce promising results in your first run.
But something seems off.
Your model seems to struggle when you deploy it in production. When faced with real-world data, the performance is not what you expected.
Problems arise when your data is insufficient, and your model cannot extract adequate information. Moreover, many open-source datasets are tiny because data collection is tedious and frustrating.
To solve the problem of data scarcity, we use data augmentation techniques. Data augmentation allows engineers to generate new samples of data from the original data used to train the model. Data augmentation has become necessary in any Deep Learning training pipeline and has proven to be particularly helpful in the case of computer vision (CV).
But how do you augment image data? Let's discuss the process in detail.
What Is Image Data Augmentation?
Image data augmentation is the process of generating new transformed versions of images from the given image dataset to increase its diversity.
To a computer, images are just a 2-dimensional array of numbers. These numbers represent pixel values, which you can tweak in many ways to generate new, augmented images. These augmented* *images resemble those already present in the original dataset but contain further information for better generalization of the machine learning algorithm.
In a CVOps pipeline, image data augmentation is beneficial for improving the performance of object detection, classification, or segmentation models. More on this in the next section.
Why Use Data Augmentation in Computer Vision?
For deployable computer vision solutions, more extensive datasets are preferable; datasets that cover all visual aspects of a target object. But this is easier said than done.
Image data collection requires manual capturing and annotations of images, and it is impossible to capture every single scenario that may be useful for the computer vision model.
Say you want to collect images of scenic landscapes for a CV project. It is not humanly possible to capture pictures in all lighting conditions. No matter how hard you try, your dataset will always have some information missing, which limits the ability of your CV model to learn, and the final output might not be as expected. Data augmentation techniques can help create new images to fill in this missing data.
Image data augmentation saves several person-hours that would otherwise be spent trying to build the perfect dataset. It allows you to improve your model's performance using your existing dataset by protecting it from overfitting.
We just introduced a new term there; let's talk more about overfitting.
Overfitting–What, Why, & When?
A common problem with underperforming machine learning models is overfitting.
When your model has an excellent training score but fails to perform on real-world test data, the model is said to have over-fitted.
To explain it further, modern machine learning models can learn discreet underlying patterns with high precision. They can perform very well on data they have seen, but the model may not be able to distinguish similar patterns from unseen examples. It is so used to seeing the training examples that it cannot develop familiarity with new data points.
Typically, overfitting occurs when you have a small dataset. A small dataset means your machine learning model has only a limited number of patterns available for learning.
Let's say you want to build a cat classifier, but you only have images of black cats. The model might never fail to identify a black cat, but it will struggle for cats of different colors and breeds. The same would be the case if the images captured are all from the same angle; the model will demonstrate poor performance if your test image is from a changed perspective.
Luckily there are multiple solutions available for such a problem. Computer vision researchers have developed several augmentation techniques to extend a dataset and improve model performance.
Let's discuss these image augmentation techniques in detail.
Image Augmentation Techniques for Computer Vision
Image data is perhaps one of the easiest to augment due to the wide-ranging availability of relevant techniques. This plethora of augmentation techniques performs very well for computer vision tasks. Some of these include:
- Position Manipulation:
 Image data augmentation
Image data augmentation
You can change the image position in many different ways. Position manipulation methods include:
- **Scaling: **Increase or decrease the picture size.
- **Rotation: **Rotate the image to generate new angles.
- **Flipping: **Flip the image left, right, or upside down.
- Color Manipulation:
 Image data augmentation
Image data augmentation
The colors of an image hold vital information for the machine learning models. We can change these colors for different effects. Examples of such tweaks are:
- Brightness
- Contrast
- Saturation
- Hue
Changing the above settings can help us create different lighting conditions. These modified images can be helpful in situations like the one discussed in the section "Why Use Data Augmentation in Vision?".
- Image Manipulation:
You can manipulate images in multiple ways to synthesize data representing different situations. We can use the following techniques for image augmentation:
- **Blur: **Images can be blurred using different kernel configurations depending on the amount of blur required. Blur allows us to generate pictures with varying levels of focus and degraded image quality.
 Image data augmentation
Image data augmentation
- **Sharpening: **Sharpness has the opposite effect on an image compared to blur, but it serves the same purpose; to get different levels of focus and higher image clarity.
- **Random cropping: **Randomly crop out bits and pieces from an image, allowing the model to learn from non-perfect data, which is a better fit for real-world situations.
 Image data augmentation
Image data augmentation
We can use all the methods mentioned above to increase the size of our dataset manifold. Augmentation can save hours of manual data annotation; however, with so many techniques available, it can also be a cumbersome task.
Luckily, Picsellia's automated CVOps pipeline gives you complete control over your dataset. You can choose from several different augmentation techniques and construct a custom pipeline. Picsellia's smart feedback loop allows you to retrain your model with modified data and different parameter configurations. Its model monitoring system keeps track of which models and parameters perform best.
Takeaways
Data scarcity can be a nightmare for computer vision engineers because data collection is frustrating. It requires several hours of work to collect and manually annotate images.
To tackle this problem, you can use data augmentation techniques to synthesize more data from the existing example image set. These techniques help generate image data, providing CV models with new information that can help them understand the data better and improve its performance.
Picsellia offers an automated CVOps pipeline built with advanced computer vision techniques. Our integrated image labeling tools and built-in data augmentation module allows hassle-free management of data. To know more about our platform, book your demo today! It'll only take a few minutes to understand your use-cases and offer your a free trial.
Related from Picsellia
Organize and version your datasets
Version, slice, and manage datasets with full traceability — from raw images to production-ready splits.
Explore Dataset ManagementAnnotate faster with AI assistance
Picsellia's labeling tool supports bounding boxes, polygons, and segmentation masks with built-in AI assistance to speed up annotation.
Explore the Labeling ToolStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles

Computer Vision Dataset Slicing
Discover dataset slicing, a technique used to divide large datasets into smaller parts to train and test models and improve model accuracy.
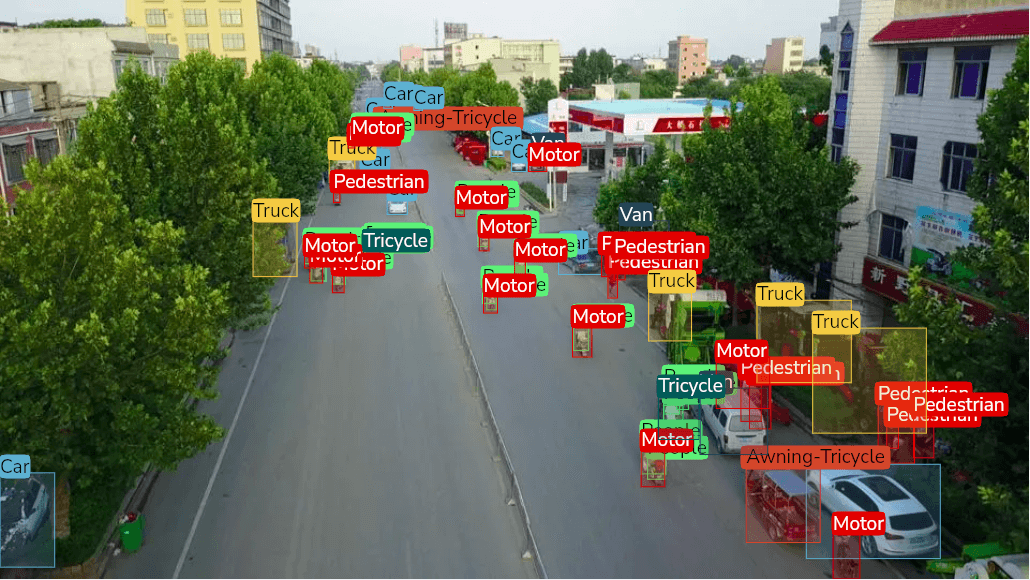
Best object detection datasets in 2024
Looking to train your object detection models? Discover a wide variety of high-quality object detection datasets to fuel your AI projects.
Data-Centric AI: A Guide to Improving ML Performance Through Data
Learn how the benefits of Data-Centric AI, a new paradigm focusing on improving data quality applies to computer vision.