Insights & Tutorials
Practical guides on computer vision, MLOps workflows, and building production AI — written by the Picsellia team and community.
The Cost of Tool-Switching in Computer Vision Pipelines
Tool overhead isn't additive — it compounds. Learn how context switching between ML tools costs CV teams hundreds of engineering hours per year.

Introducing Picsellia Atlas: An Open-Source AI Co-Pilot for Advanced Vision AI Development
Picsellia Atlas: an open-source AI co-pilot to streamline custom Vision AI development, boosting data quality, model precision, and workflow efficiency.

From Computer Vision to Industry 4.0: How Scortex Is Shaping Automated Visual Inspection
Discover how Scortex leverages AI and computer vision for automated visual inspection, from defect detection to anomaly detection and real-time insights.

Introducing Picsellia Community Edition
Accelerate your VisionAI journey with Picsellia Community Edition, the free version of Picsellia.

Mastering Data Annotation for AI Projects in 2025
This article will discuss the importance of data annotation in AI and the best practices and strategies for overcoming labeling hurdles.

2025 Trends in Computer Vision: What to Expect
Learn about the upcoming Computer Vision trends in 2025.

AI for Livestock Monitoring: Enhancing Animal Welfare and Farm Productivity
Learn how AI helps manage animal well-being and farm productivity. Get to know about benefits of using AI in every day farming.

Picsellia at Big Data & AI Paris 2024
Read about Picsellia's experience at Big Data & AI Paris, 2024.

AI-Powered Video Analytics for Intelligent Surveillance in Smart Cities
Discover how AI video analytics transforms smart city surveillance, enhancing safety, real-time crime detection, traffic management, and data security.

Precision Agriculture: Using Computer Vision for Crop Health Monitoring
Explore how computer vision in precision agriculture boosts crop health by detecting issues early, optimizing resources, and increasing yields efficiently.

Coolest Startups in the Agtech Space
Learn about companies that are optimising technology for agriculture.

Early Adopters of Computer Vision
Learn more about the companies that first adopted and used computer vision.
Hyperparameter Tuning in Computer Vision
In this article, you will learn about the importance of hyperparameters, where, when and how to tune them.

The Concept of Synthetic Data for Curating Optimized Manufacturing Datasets
Learn how optimized datasets improve AI models and production efficiency in today’s data-driven world.

SAHI Revisioned
Picsellia's new tiling model improves object detection by preserving resolution, especially for smaller objects, while offering flexible tiling modes.

Top Datasets for Computer Vision
Comprehensive guide to top datasets useful for computer vision.

A Breakdown of AI Costs for Your Organization
Breakdown of AI development costs in 2024, including infrastructure, labor, software, and tips to optimize expenses for successful implementation.

Learn Computer Vision: Beginner’s Guide
Discover top resources for learning computer vision, from OpenCV tutorials to advanced Coursera courses. Ideal for beginners!

Optimise Data Exploration with Enhanced Visual Search
Discover how visual search changes image data exploration, enabling efficient cleaning, object detection, and image- and text-based searches

Safer Pipelines, Smarter Energy: Using Computer Vision for Pipeline Inspections
Make pipeline inspection more rigorous with Computer Vision. Learn more about how Computer Vision can help prevent disasters at the energy site.

Leveraging Computer Vision for Smarter Production Lines
Discover how computer vision is transforming production lines to improve efficiency, reduce errors, and boost product quality in manufacturing industry.

EU's Green Revolution: How Technology is Changing Waste Management
Discover how companies in the EU are using Computer Vision technology to drive innovation in waste management for a more sustainable future.

An Introduction to Object Tracking in Computer Vision
Learn how object tracking builds on object detection by tracking objects over time. Explore key differences, challenges, and effective techniques.

Meet piSAM: The Newest Addition to Picsellia's Computer Vision Toolbox
Meet piSAM, the Picsellia Segment Anything Model. piSAM offers fast, accurate image segmentation with a single click. Enhance your vision AI projects.

VLMs vs. CNNs: Is a New Era Dawning in Computer Vision Performance?
Discover if Vision Language Models (VLMs) outperform Convolutional Neural Networks (CNNs) in computer vision.

Integrating Picsellia in Your Databricks/MLFlow Environment
Combine MLFlow's management with Picsellia's specialized tools for efficient, streamlined workflows.

Build High-Performing Teams for Computer Vision Projects
Looking to build high-performing teams? Explore the key data team roles required to excel in the field of computer vision.

The Art of Annotation: Lessons Learned From a Picsellia Annotation Campaign
Discover invaluable insights from Picsellia's annotation marathon in Spain. Learn how Picsellia revolutionized annotation campaigns for optimal results.

Introducing Picsellia v3.0
Discover the latest release, Picsellia Platform v3.0, tailored to revolutionize the computer vision landscape. From enhanced annotation tools for video lab

A guide to Tag Image File Format (TIFF): Leveraging High-Pixel Quality for Computer Vision Applications
TIFF files are a raster image file format commonly used for storing high-quality images. Discover how they work here.

Leveraging Energy Datasets: Transforming Infrastructure with Computer Vision
Explore how energy datasets drive efficiency and safety through computer vision solutions in the infrastructure sector.
What is video annotation for computer vision?
Looking for video annotation and computer vision services? Enhance your AI algorithm models with accurate and comprehensive data.

Top Computer Vision Datasets for Manufacturing
Access extensive and reliable manufacturing datasets to power your AI and machine learning projects.

Going beyond the Basics of Anomaly Detection in Computer Vision
Find out how anomalies in visual data can be detected using computer vision tools.

Computer Vision Dataset Slicing
Discover dataset slicing, a technique used to divide large datasets into smaller parts to train and test models and improve model accuracy.
Best object detection datasets in 2024
Looking to train your object detection models? Discover a wide variety of high-quality object detection datasets to fuel your AI projects.
Anomaly Detection in Manufacturing Lines Using Computer Vision
Discover the challenges and benefits of visual anomaly detection systems in manufacturing.

DINOv2 - Steps by steps explanations - Picsellia
Discover DINOv2, an upgrade of DINO. Try using a self-supervised method applied to Vision Transformers. This method enables all-purpose visual features.

What is OCR? Optical Character Recognition Software Explained
In-depth dive into OCR, from its definition and history to its underlying technologies and the most common (and valuable) applications.

How to Integrate Picsellia into a Hugging Face Training Workflow
Effortlessly scale computer vision model training with Picsellia's CVOps platform and HuggingFace.
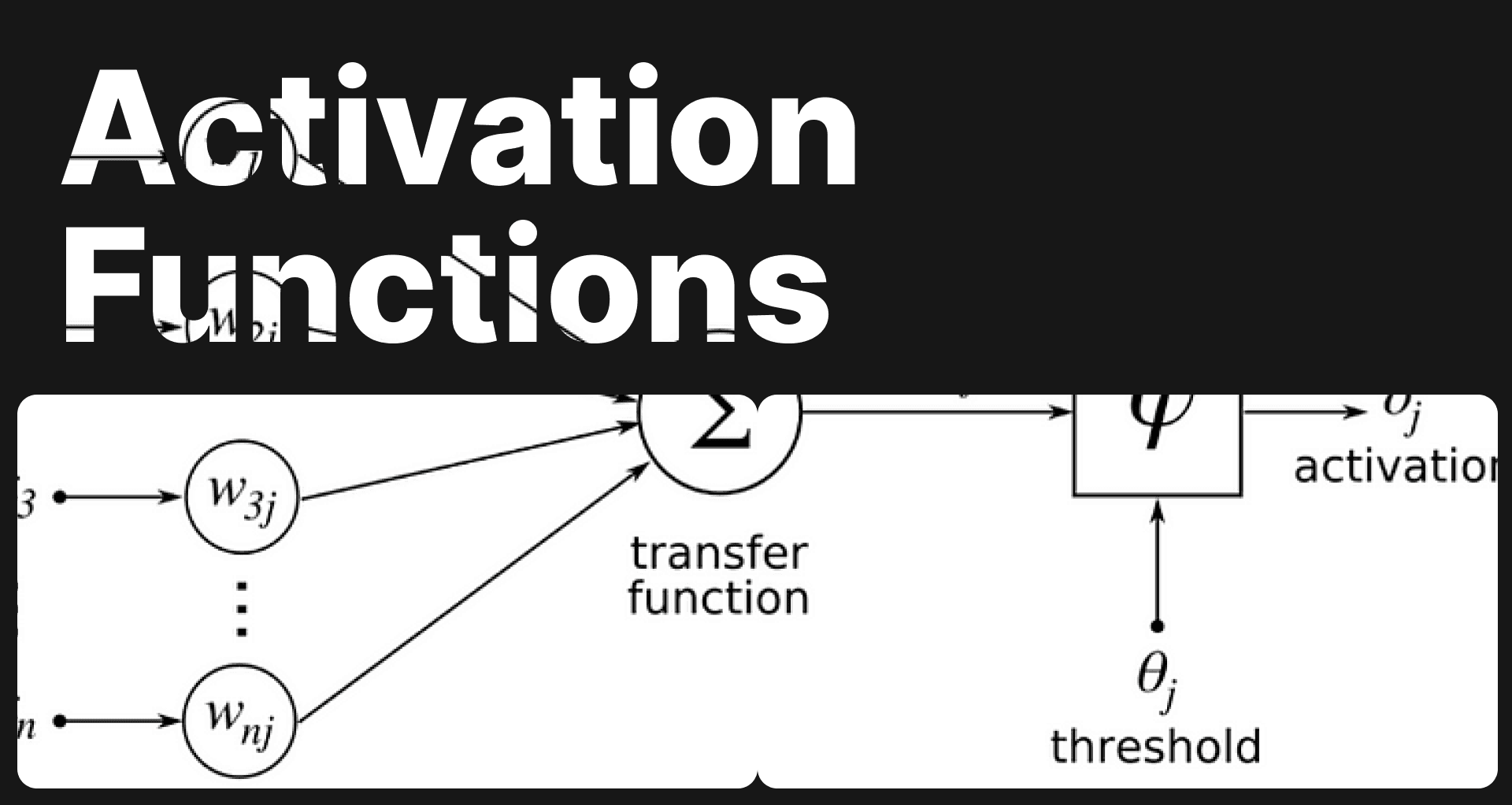
Activation Functions and Neural Networks
Explore the key roles of activation functions in neural networks for computer vision tasks. Learn about Sigmoid, ReLU, and more for better deep learning.

COCO Evaluation metrics explained
Dive into COCO Evaluation Metrics for computer vision, exploring precision, recall, IoU & their meaning. Master object detection with Picsellia.
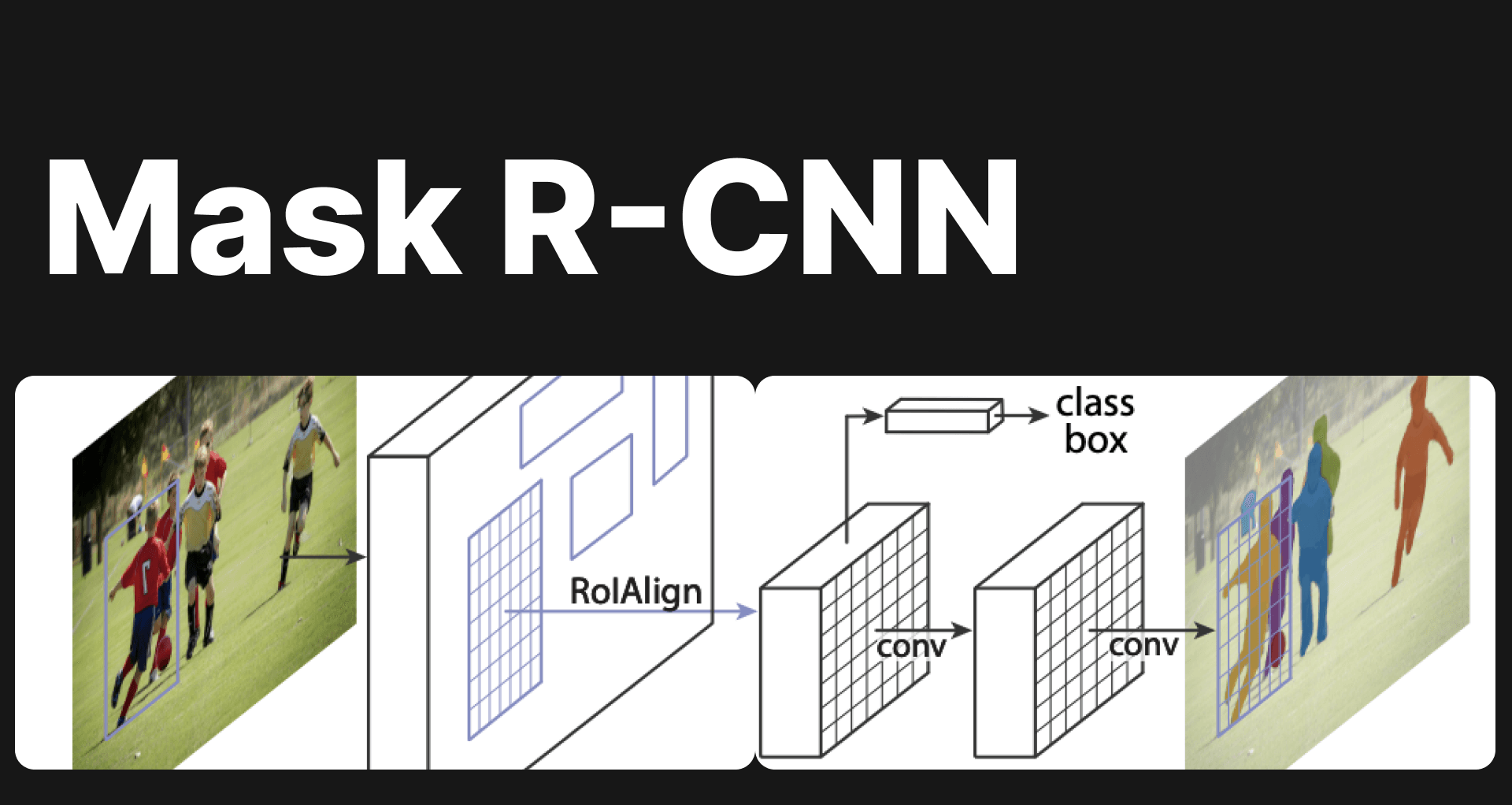
Mask R-CNN - Everything explained
Explore Mask R-CNN: a groundbreaking tool in computer vision for object detection & instance segmentation. Dive deep into its architecture & applications.

Understanding Overfitting in Machine Learning
Learn to tackle overfitting in machine learning with effective strategies and Picsellia's MLops platform. Avoid model memorization.

The Confluence of Computer Vision and Drone Technology
Unlike their early counterparts, today's drones are not just equipped to capture high-resolution images and videos, AI opened up a whole new field.
![[Industrie 4.0] Revolutionizing Manufacturing with Computer Vision](/_next/image?url=%2Fimages%2Fblog%2Findustrie-4-0-revolutionizing-manufacturing-with-computer-vision-hero.png&w=3840&q=75&dpl=dpl_FbzTF4dT5o31GMiA3kRaKrFL1uv9)
[Industrie 4.0] Revolutionizing Manufacturing with Computer Vision
The integration of computer vision technology in modern manufacturing has opened up a world of possibilities for companies looking to streamline their work

An In-Depth Guide to Contrastive Learning in AI
Contrastive learning is a machine learning technique that teaches models to distinguish between similar and dissimilar samples.

Exploring Stable Diffusion: Revolutionizing Image-to-Image Generation in Computer Vision
Stable diffusion is a type of generative model, which uses the power of AI and deep learning to generate images. Let’s take a closer look at it.

Top 5 experiment tracking tools for Computer vision
AI is typically achieved through iterative and experimental processes such as changing the model, running multiple experiments, and examining the results.

Image Embeddings explained
In a nutshell, embedding is a dimensionality reduction technique. It is a lower dimensional vector representation of high dimensional feature vectors (i.e.

Segmentation vs Detection vs Classification in Computer Vision: A Comparative Analysis
Explore the nuances of Segmentation, Detection, and Classification in Computer Vision. A detailed comparative analysis for a comprehensive understanding.

Understanding the F1 Score in Machine Learning: The Harmonic Mean of Precision and Recall
In this article, we will delve into the concept of the F1 score, its relationship with precision and recall, andwhy it is advantageous to use the F1 score.

SAM and Foundation Models in Computer Vision
We explored how SAM was created to become such a powerful tool. A groundbreaking model not only for Meta, but for the entire computer vision scenario!
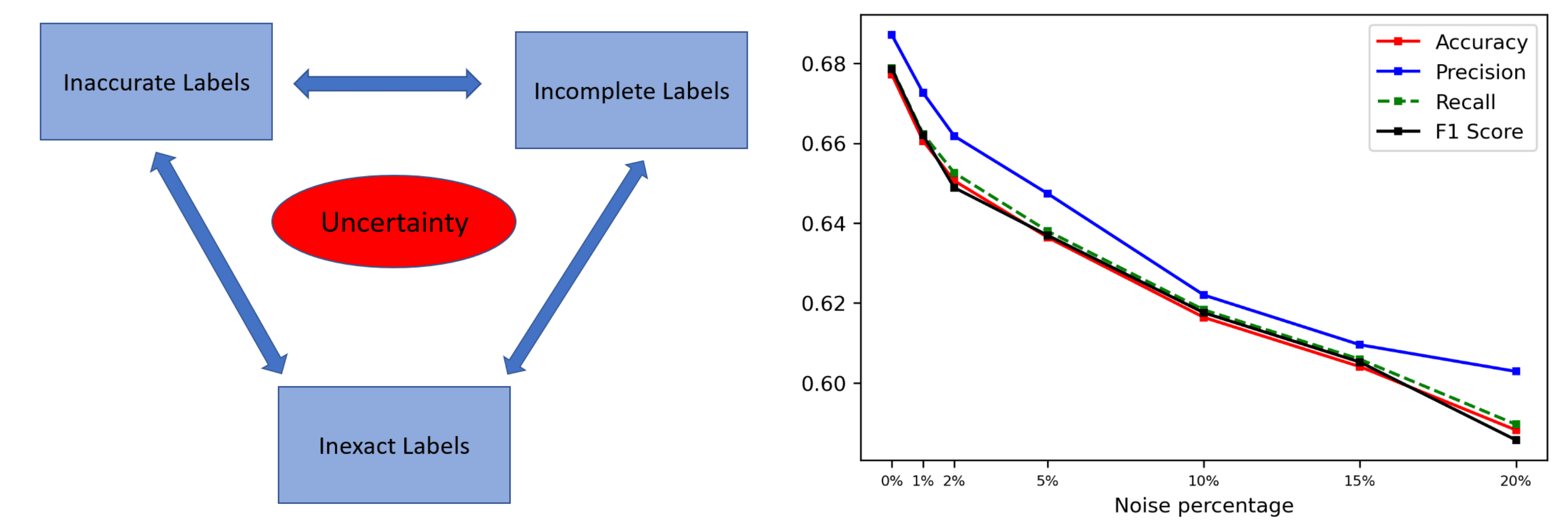
Data-Centric AI: A Guide to Improving ML Performance Through Data
Learn how the benefits of Data-Centric AI, a new paradigm focusing on improving data quality applies to computer vision.

Onboarding New Collaborators Easily
High turnover rates are real. There are many reasons behind people’s growing tendency to change teams, such as career changes, internal move, gap year.
Best Practices for Fine-Tuning Computer Vision Models
This article will introduce you to the best practices for hyperparameter tuning, explored through a typical CV task with TensorFlow and Keras-Tuner.
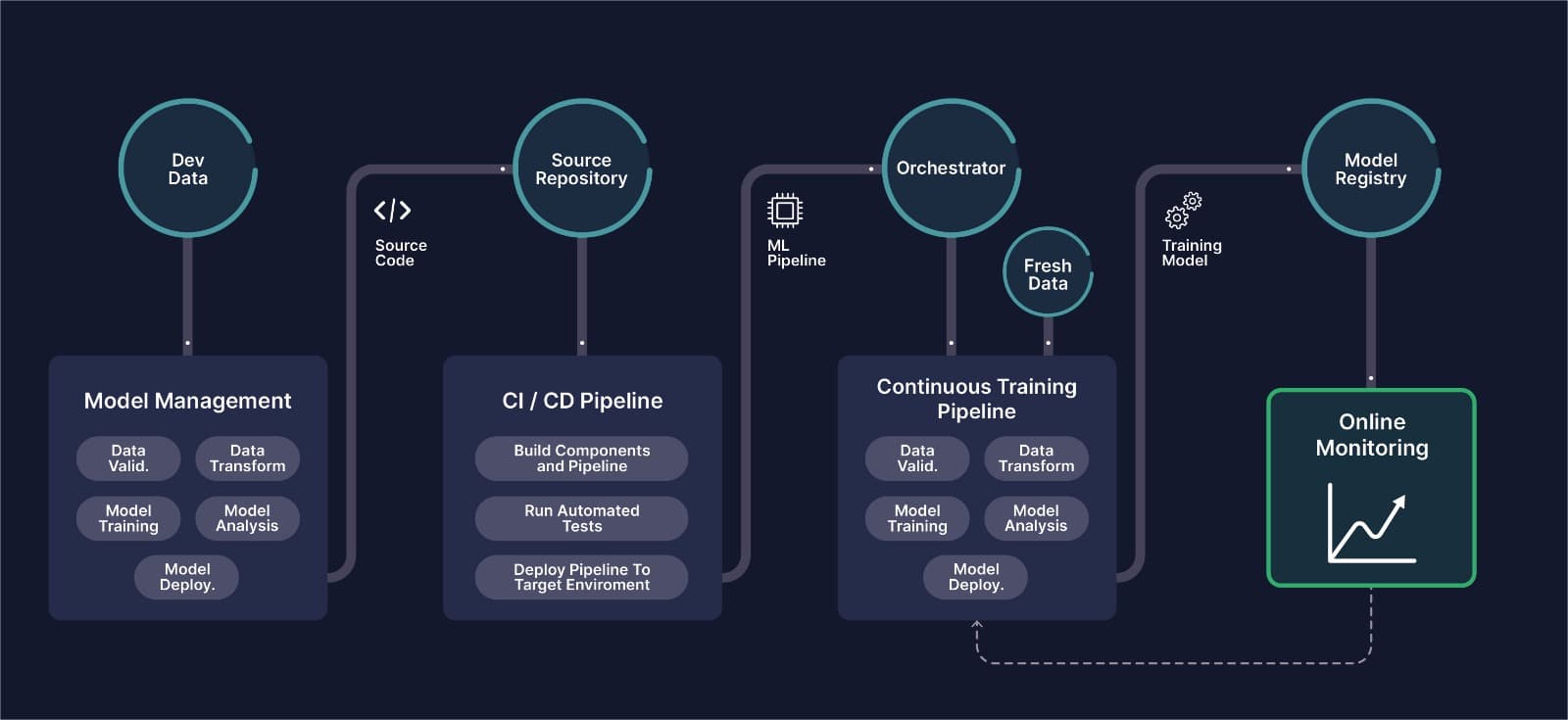
End-to-End Repeatable MLOps for Computer Vision
Any enterprise ML pipeline should automate various steps in the ML lifecycle. Such automation is usually achieved by compartmentalising each step as a stan
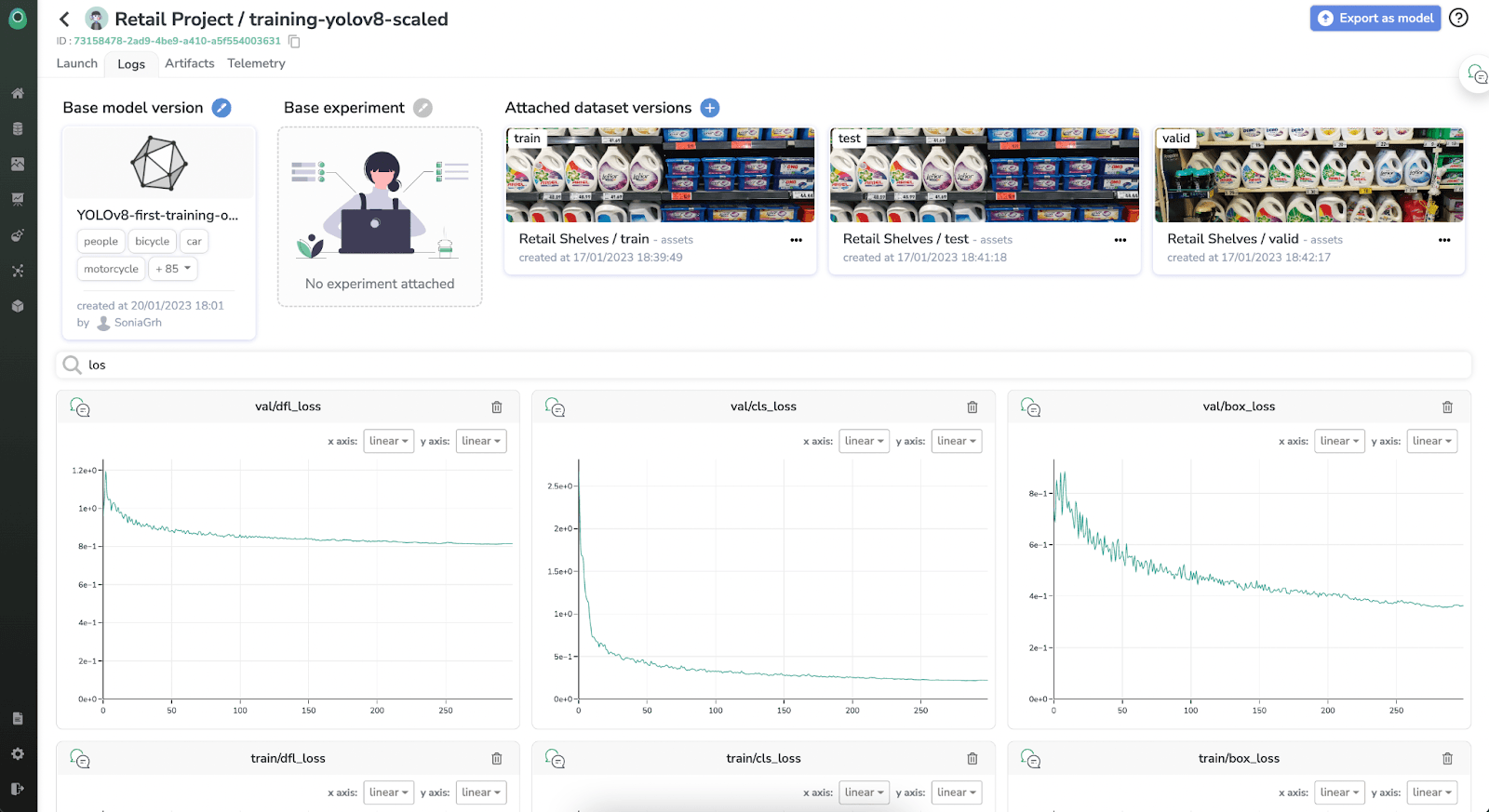
Train and integrate YOLOv8 with Picsellia in just a few minutes
In this tutorial, we will provide you with a detailed guide on how to train the YOLOv8 object detection model using Picsellia.
How to train YOLOv8 on a custom Dataset
YOLOv8 is the most recent edition in the highly renowned collection of models that implement the YOLO (You Only Look Once) architecture.

Is AutoML Replacing Data Scientists?
Machine Learning revolutionized computer vision and language processing and is now shapeshifting biology and engineering.

5 Ways Computer Vision Simplifies PCB Design and Workflows
Computer vision operations can be used to automate many of the tasks involved in working with PCBs, making the process faster and more accurate.
5 Steps to Take To Start A Career in Computer Vision
Have you ever wondered how to break into the field of computer vision? Here are some cool tips on how to get started!

That’s a wrap!
Our CEO Thibaut reflects on the past year and shares with us what he's learned in terms of computer vision, entrepreneurship, and enlarging the avo family!

How to Deal with Imbalanced Datasets in Computer Vision
Imbalanced datasets lead to problems with accuracy, overfitting, and bias. Data augmentation, class weighting and hierarchical classification can help.

A dive into YOLO object detection
We will explore the family of YOLO object detection models, from the original YOLO network up to the latest YOLOv8 and NAS networks.

6 Computer Vision Trends in 2022
Explore the upcoming AI trends for 2022.

How To Ensure Data Quality – Best Practices
Data curation is the management of data in an organization such that it is readily available in the present and preserved for future use
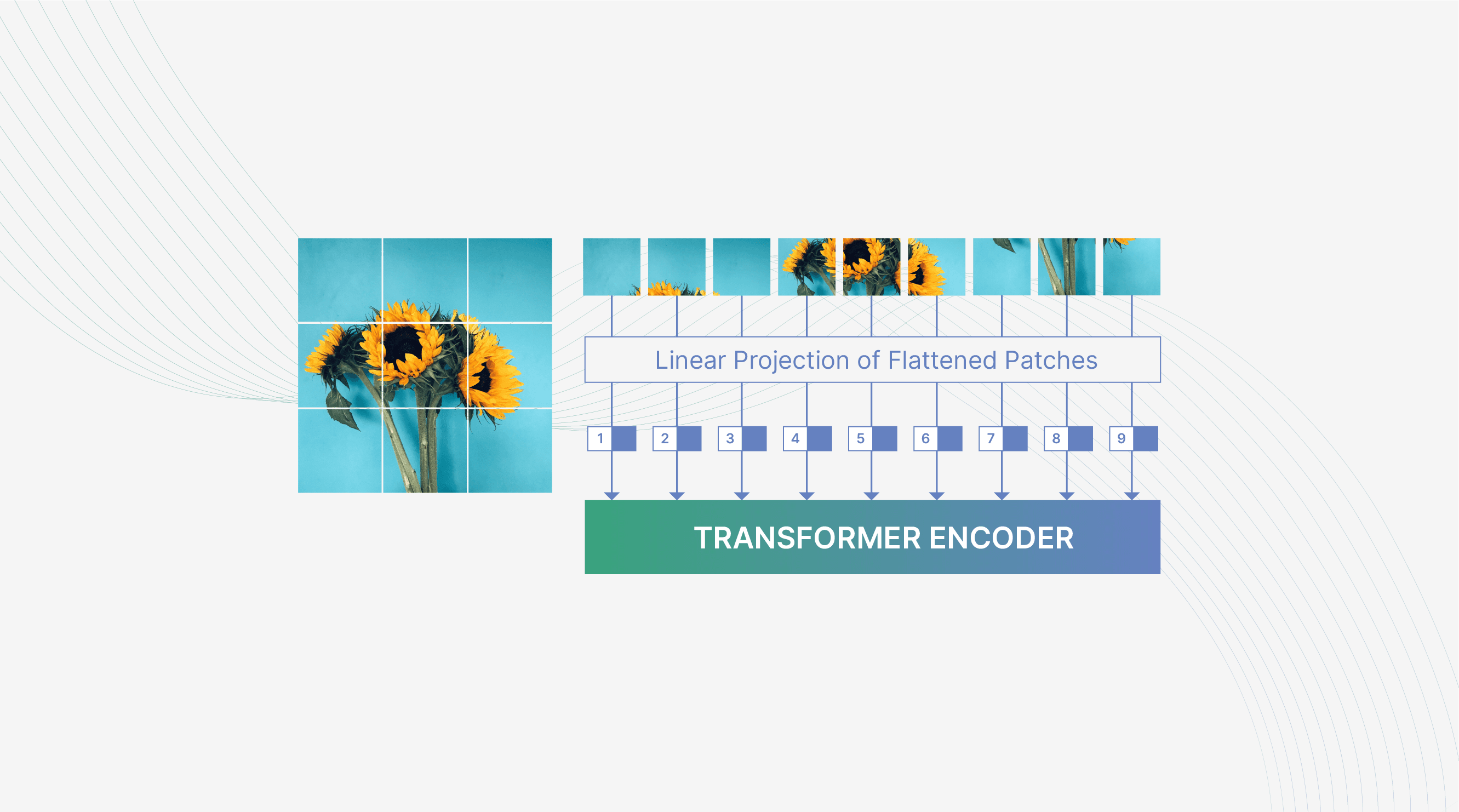
Are Transformers replacing CNNs in Object Detection?
In the past decade, CNNs sparked a new revolution in computer vision. In 2020, ViTs gained a lot of attention. Are transformers replacing CNNs?
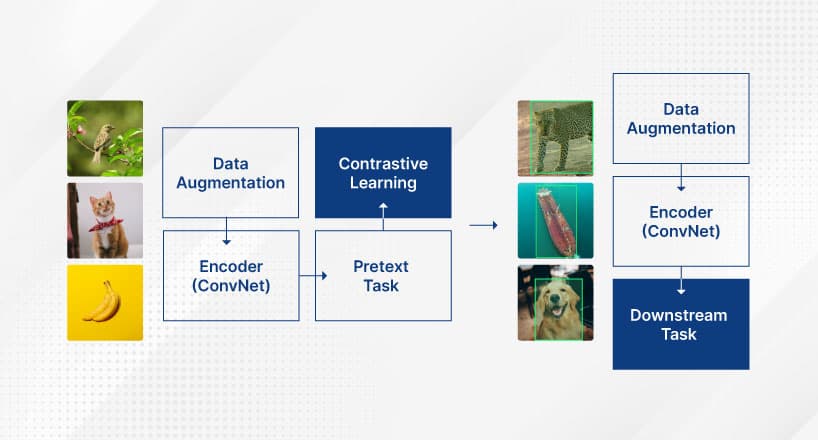
How to Reduce Training Data with Self-Supervised Learning
Self-Supervised Learning (SSL) aims to leverage large unlabeled datasets to train capable feature extractors such as CNN or ViT encoders. But what is SSL?

What Is Image Data Augmentation?
To solve the problem of data scarcity, we use data augmentation techniques. But how do you augment image data? We'll go throw this in a simple way.

Why Do Classical MLOps Tools Not Fit Computer Vision?
Computer vision pipelines require a set of processes that are exclusive to Computer Vision. This is where CVOps comes to play.

How To Optimize Computer Vision Models For Edge Devices
Learn the best optimization techniques to decrease model size and increase inference speed in computer vision.

Data Versioning & Feedback Loop Best Practices
Data versioning is an effective methodology used when running many experiments that entail different data processing techniques. Find our best practices!
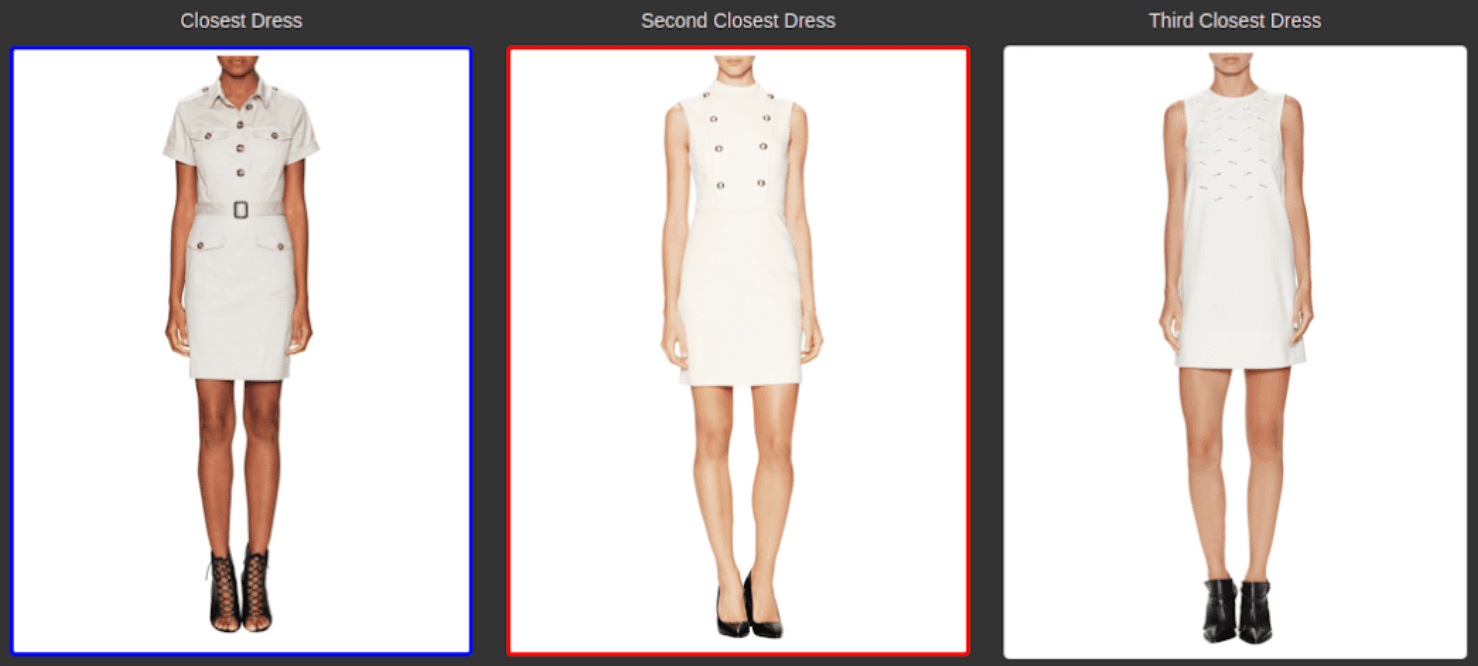
How We Built A Dataset Visual Similarity Search Feature
Learn how we built a dataset visual similarity search feature with embeddings and Qdrant.

Key Metrics To Monitor Computer Vision Solutions
In computer vision high-quality training data doesn't ensure high-performing production models. The work begins after deployment, and monitoring is a must.

Data Management in AI: Key Success Factor
Learn about key success factors for data management in AI.

How to Use Computer Vision in Cancer Research With MLOps
We introduced Picsellia's new features by presenting a cancer cell research real use-case. Learn how we applied computer vision to medical research.
How to Train YOLOv5 on a Custom Dataset, Step by Step
We'll show you the step by step of how to easily train a YOLOv5, by using a complete MLOps end-to-end platform for computer vision use-cases.

Creating a CVOps Platform: Picsellia’s Latest Release is Out
Our new release incorporates the latest tools and features to manage your entire MLOps pipeline in one single place, making it the first CVOps platform.

How Roc4t Used Picsellia For Its Computer Vision Projects
Roc4Tech is an AI company dedicated to video analysis and smart cameras. In this article, its CEO and CTO will go through his experience with Picsellia.
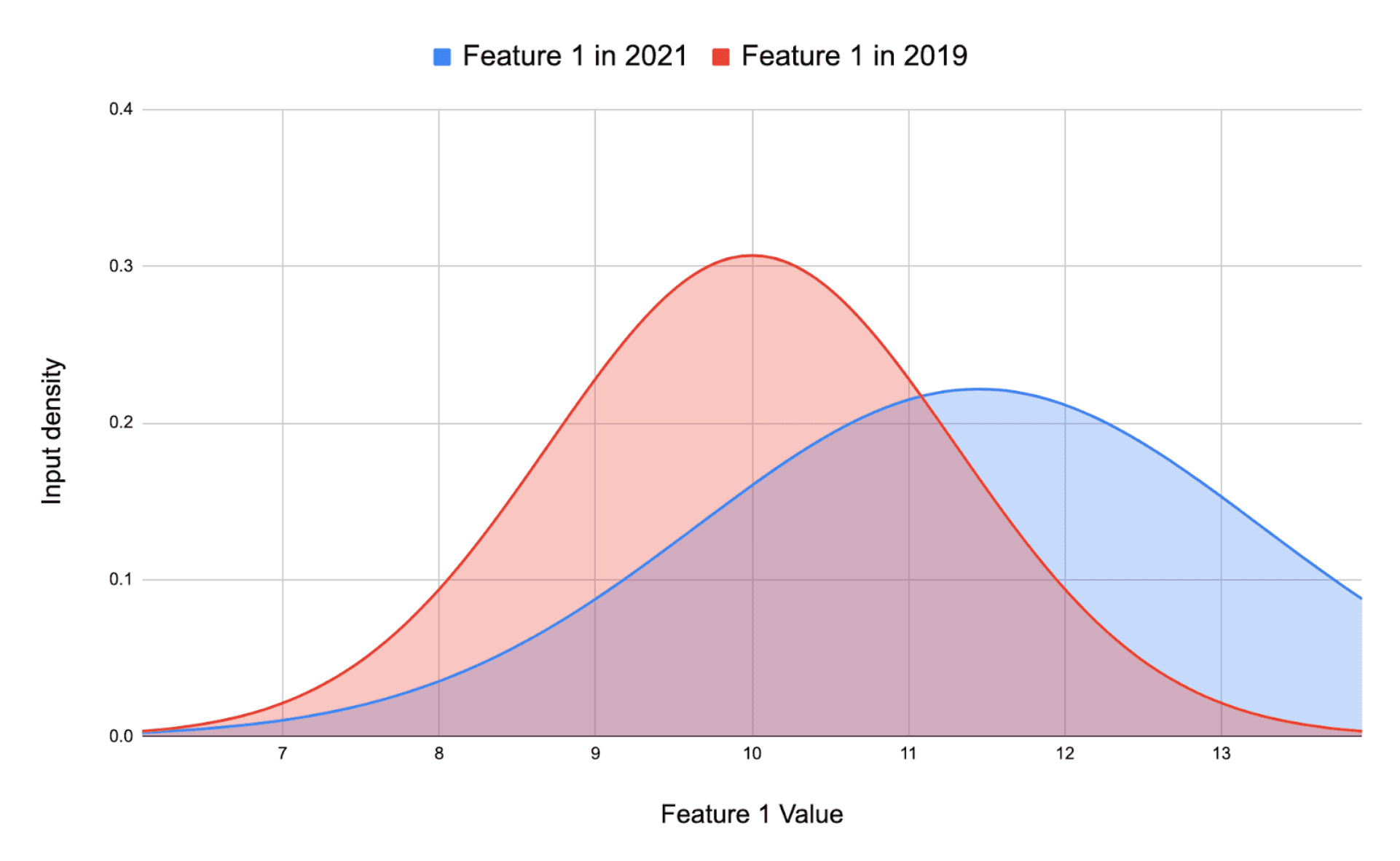
What is Data Drift and How to Detect it in Computer Vision?
Data-drift happens when the dataset that used to train your model doesn't mimic the data you receive in production, causing your model to underperform.

MLOps Platform: Build vs. Buy? What You Must Know
Some companies go for building entire MLOps platforms, while others decide to purchase tools that integrate to their solutions. Learn what's best for you.

How to Ensure Image Dataset Quality In Image Classification
Learn how to tackle the dataset quality main issues, and how to optimize the overall quality of your AI models for image classification use-cases.

4 Things to Consider To Choose a Data Management Platform
Working with large datasets can be challenging. If you don't know what elements to consider when picking a data AI platform, then this article is for you.

How to apply MLOps to Computer Vision? Introducing CVOps
CVOps refers to the steps and processes of MLOps that are exclusive to Computer Vision, to achieve the development and deployment of CV use-cases.

How Capgemini Used Picsellia to Deliver AI Models Faster
Learn how Capgemini, the French multinational IT and consulting company, leveraged Picsellia to deliver their AI models faster.

Road to MLOps — Level 2: Part 3
MLOps level 2 goes a step further in terms of the kind of system that we are now able to operate. By that we mean large-scale, high-frequency systems.

Road to MLOps — Level 1: Part 2
What is level 1 and level 2 in MLOps, and how are they different from level 0 MLOps?

What is MLOps? And Why is it Important? Part 1
MLOps, short for Machine Learning Operations, is a discipline that aims to unify ML system's development and deployment to optimize high-performing models.
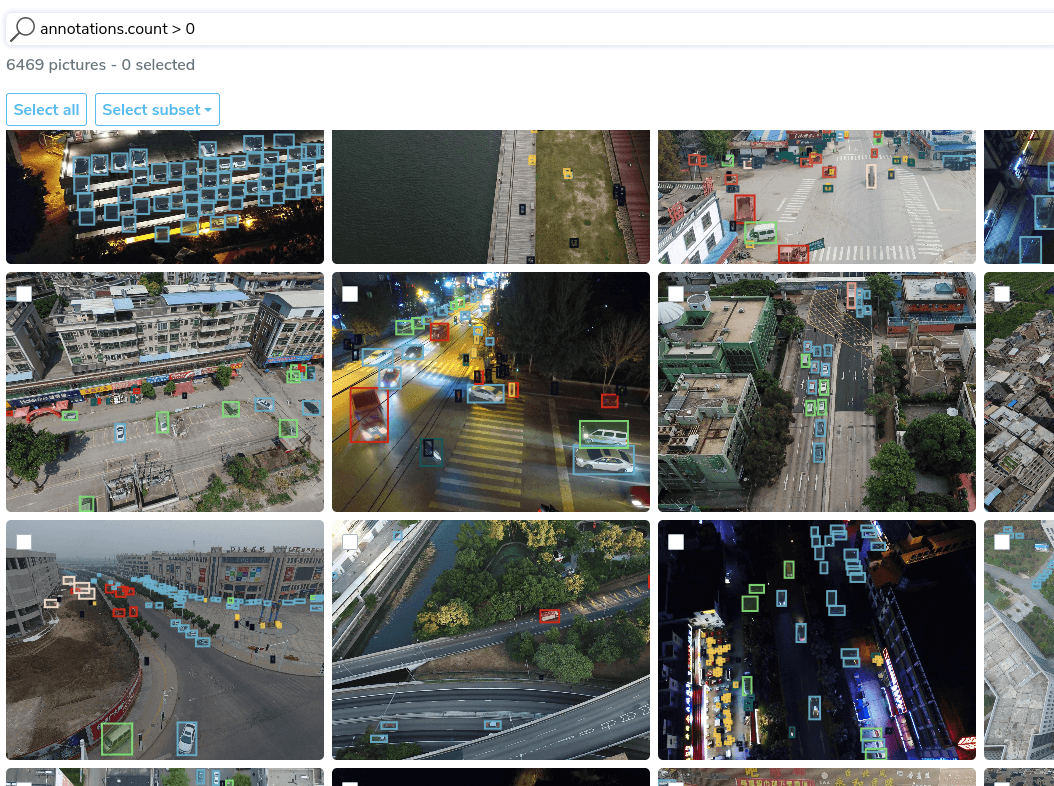
Data-Centric AI vs. Model-Centric AI? Which one will win?
Today, we've gone from model-centric to data-centric AI. We will walk you through the history of data-centric AI and where it's going in the next years!
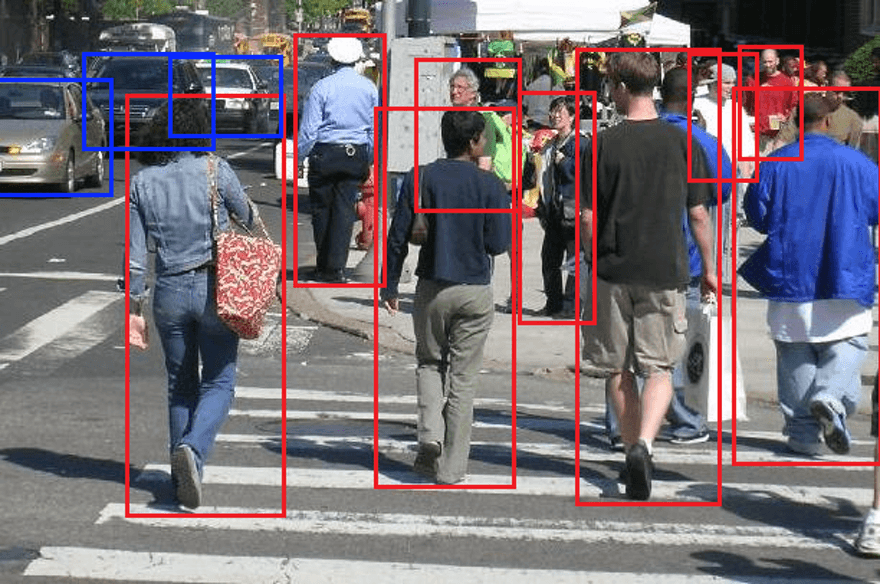
Ensuring the Success of an ML Computer Vision Project
There are many pros in having a computer classify and categorize images or objects. But how can you guarantee the success of your computer vision project?

How to Build an Image Anonymizer For GDPR Compliant Tasks With TF2
Our mission is to assist others to build better computer vision models, so we built an anonymizer to help you build GDPR-compliant human-related datasets.

The Fastest Way to Analyze Models for Object Detection
Learn how to choose, tune and train any deep learning architecture to train your object detection models, by using an MLOps solution for computer vision.
Stay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.