Qu'est-ce que l'augmentation de données d'images ?
Pour résoudre le problème de rareté des données, nous utilisons des techniques d'augmentation de données. Mais comment augmenter des données d'images ? Nous allons l'expliquer simplement.
Picsellia Team
·7 min read

Organisez vos donnees visuelles des aujourd'hui
Versionnez vos datasets, gerez les annotations et tracez la lignee depuis un seul endroit.
Vous aviez une idée révolutionnaire pour un projet de machine learning (ML) et avez trouvé un excellent dataset en ligne. Vous entraînez ces données en utilisant des techniques ML à l'état de l'art et produisez des résultats prometteurs lors de votre première exécution.
Mais quelque chose semble clocher.
Votre modèle semble avoir des difficultés lorsque vous le déployez en production. Face aux données du monde réel, la performance n'est pas celle que vous attendiez.
Les problèmes surviennent lorsque vos données sont insuffisantes et que votre modèle ne peut pas extraire d'informations adéquates. De plus, de nombreux datasets open source sont de petite taille car la collecte de données est fastidieuse et frustrante.
Pour résoudre le problème de rareté des données, nous utilisons des techniques d'augmentation de données. L'augmentation de données permet aux ingénieurs de générer de nouveaux échantillons de données à partir des données originales utilisées pour entraîner le modèle. L'augmentation de données est devenue nécessaire dans tout pipeline d'entraînement de deep learning et s'est révélée particulièrement utile dans le cas de la vision par ordinateur (CV).
Mais comment augmenter des données d'images ? Discutons du processus en détail.
Qu'est-ce que l'augmentation de données d'images ?
L'augmentation de données d'images est le processus de génération de nouvelles versions transformées d'images à partir du dataset d'images donné pour augmenter sa diversité.
Pour un ordinateur, les images ne sont qu'un tableau bidimensionnel de nombres. Ces nombres représentent des valeurs de pixels, que vous pouvez modifier de nombreuses manières pour générer de nouvelles images augmentées. Ces images augmentées ressemblent à celles déjà présentes dans le dataset original mais contiennent des informations supplémentaires pour une meilleure généralisation de l'algorithme de machine learning.
Dans un pipeline CVOps, l'augmentation de données d'images est bénéfique pour améliorer la performance des modèles de détection d'objets, de classification ou de segmentation. Plus de détails dans la section suivante.
Pourquoi utiliser l'augmentation de données en vision par ordinateur ?
Pour des solutions de vision par ordinateur déployables, des datasets plus étendus sont préférables ; des datasets qui couvrent tous les aspects visuels d'un objet cible. Mais c'est plus facile à dire qu'à faire.
La collecte de données d'images nécessite la capture manuelle et l'annotation d'images, et il est impossible de capturer chaque scénario unique qui pourrait être utile pour le modèle de vision par ordinateur.
Supposons que vous vouliez collecter des images de paysages pittoresques pour un projet CV. Il n'est humainement pas possible de capturer des photos dans toutes les conditions d'éclairage. Quels que soient vos efforts, votre dataset aura toujours des informations manquantes, ce qui limite la capacité de votre modèle CV à apprendre, et le résultat final pourrait ne pas être celui attendu. Les techniques d'augmentation de données peuvent aider à créer de nouvelles images pour combler ces données manquantes.
L'augmentation de données d'images économise de nombreuses heures-personnes qui seraient autrement consacrées à essayer de construire le dataset parfait. Elle vous permet d'améliorer la performance de votre modèle en utilisant votre dataset existant en le protégeant du surapprentissage.
Nous venons d'introduire un nouveau terme ; parlons davantage du surapprentissage.
Surapprentissage – Quoi, pourquoi et quand ?
Un problème courant avec les modèles de machine learning sous-performants est le surapprentissage.
Lorsque votre modèle a un excellent score d'entraînement mais échoue sur les données de test du monde réel, on dit que le modèle a sur-appris.
Pour l'expliquer davantage, les modèles de machine learning modernes peuvent apprendre des motifs sous-jacents discrets avec une grande précision. Ils peuvent très bien performer sur des données qu'ils ont déjà vues, mais le modèle peut ne pas être capable de distinguer des motifs similaires dans des exemples non vus. Il est tellement habitué à voir les exemples d'entraînement qu'il ne peut pas développer de familiarité avec de nouveaux points de données.
Typiquement, le surapprentissage se produit lorsque vous avez un petit dataset. Un petit dataset signifie que votre modèle de machine learning n'a qu'un nombre limité de motifs disponibles pour l'apprentissage.
Supposons que vous vouliez construire un classificateur de chats, mais que vous n'ayez que des images de chats noirs. Le modèle pourrait ne jamais échouer à identifier un chat noir, mais il aura des difficultés avec des chats de différentes couleurs et races. Il en serait de même si les images capturées sont toutes du même angle ; le modèle démontrera une mauvaise performance si votre image de test est sous une perspective différente.
Heureusement, il existe de multiples solutions disponibles pour un tel problème. Les chercheurs en vision par ordinateur ont développé plusieurs techniques d'augmentation pour étendre un dataset et améliorer la performance du modèle.
Discutons de ces techniques d'augmentation d'images en détail.
Techniques d'augmentation d'images pour la vision par ordinateur
Les données d'images sont peut-être parmi les plus faciles à augmenter en raison de la large disponibilité de techniques pertinentes. Cette pléthore de techniques d'augmentation performe très bien pour les tâches de vision par ordinateur. Certaines incluent :
- Manipulation de position :
 Image data augmentation
Image data augmentation
Vous pouvez changer la position de l'image de nombreuses manières différentes. Les méthodes de manipulation de position incluent :
- Mise à l'échelle : Augmenter ou diminuer la taille de l'image.
- Rotation : Faire pivoter l'image pour générer de nouveaux angles.
- Retournement : Retourner l'image à gauche, à droite ou à l'envers.
- Manipulation des couleurs :
 Image data augmentation
Image data augmentation
Les couleurs d'une image contiennent des informations vitales pour les modèles de machine learning. Nous pouvons modifier ces couleurs pour différents effets. Des exemples de tels ajustements sont :
- Luminosité
- Contraste
- Saturation
- Teinte
Modifier les paramètres ci-dessus peut nous aider à créer différentes conditions d'éclairage. Ces images modifiées peuvent être utiles dans des situations comme celle discutée dans la section "Pourquoi utiliser l'augmentation de données en vision par ordinateur ?".
- Manipulation d'images :
Vous pouvez manipuler les images de multiples manières pour synthétiser des données représentant différentes situations. Nous pouvons utiliser les techniques suivantes pour l'augmentation d'images :
- Flou : Les images peuvent être floutées en utilisant différentes configurations de noyaux selon la quantité de flou requise. Le flou nous permet de générer des images avec différents niveaux de mise au point et une qualité d'image dégradée.
 Image data augmentation
Image data augmentation
- Netteté : La netteté a l'effet opposé sur une image par rapport au flou, mais elle sert le même objectif ; obtenir différents niveaux de mise au point et une meilleure clarté d'image.
- Recadrage aléatoire : Recadrer aléatoirement des morceaux d'une image, permettant au modèle d'apprendre à partir de données non parfaites, ce qui est mieux adapté aux situations du monde réel.
 Image data augmentation
Image data augmentation
Nous pouvons utiliser toutes les méthodes mentionnées ci-dessus pour augmenter la taille de notre dataset de manière significative. L'augmentation peut économiser des heures d'annotation manuelle de données ; cependant, avec tant de techniques disponibles, cela peut aussi être une tâche fastidieuse.
Heureusement, le pipeline CVOps automatisé de Picsellia vous donne un contrôle complet sur votre dataset. Vous pouvez choisir parmi plusieurs techniques d'augmentation différentes et construire un pipeline personnalisé. La boucle de feedback intelligente de Picsellia vous permet de ré-entraîner votre modèle avec des données modifiées et différentes configurations de paramètres. Son système de monitoring de modèles garde une trace des modèles et des paramètres qui performent le mieux.
Points clés à retenir
La rareté des données peut être un cauchemar pour les ingénieurs en vision par ordinateur car la collecte de données est frustrante. Elle nécessite plusieurs heures de travail pour collecter et annoter manuellement les images.
Pour résoudre ce problème, vous pouvez utiliser des techniques d'augmentation de données pour synthétiser plus de données à partir de l'ensemble d'images existant. Ces techniques aident à générer des données d'images, fournissant aux modèles CV de nouvelles informations qui peuvent les aider à mieux comprendre les données et à améliorer leur performance.
Picsellia offre un pipeline CVOps automatisé construit avec des techniques avancées de vision par ordinateur. Nos outils d'étiquetage d'images intégrés et notre module d'augmentation de données intégré permettent une gestion sans tracas des données. Pour en savoir plus sur notre plateforme, réservez votre démo dès aujourd'hui ! Il ne faudra que quelques minutes pour comprendre vos cas d'usage et vous offrir un essai gratuit.
Suggestions Picsellia
Organisez et versionnez vos datasets
Versionnez, decoupez et gerez vos datasets avec une tracabilite complete — des images brutes aux splits prets pour la production.
Explorer la gestion de datasetsAutomatisez vos pipelines ML
Configurez l'entrainement et le deploiement continus avec des declencheurs automatiques, des deploiements shadow et des boucles de feedback.
Explorer les pipelines automatisesRestez informe
Recevez les derniers articles sur la vision par ordinateur, le MLOps et l'IA directement dans votre boite mail.
Articles associes

Le découpage de datasets en vision par ordinateur
Découvrez le découpage de datasets, une technique utilisée pour diviser de grands ensembles de données en parties plus petites afin d'entraîner et de tester des modèles et d'améliorer leur précision.
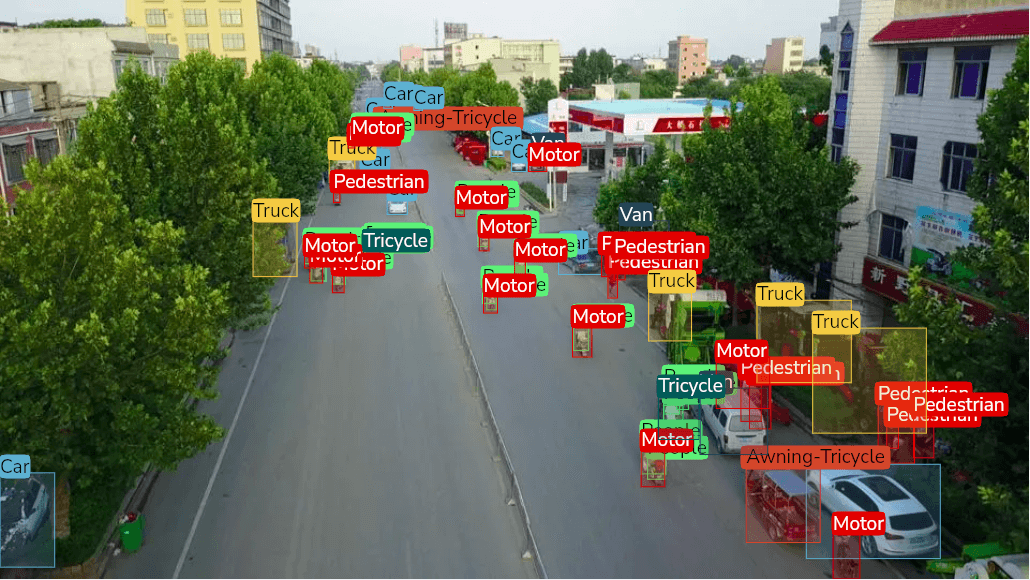
Les meilleurs datasets de détection d'objets en 2024
Vous cherchez à entraîner vos modèles de détection d'objets ? Découvrez une grande variété de datasets de détection d'objets de haute qualité pour alimenter vos projets d'IA.
Data-Centric AI : un guide pour améliorer les performances ML par les données
Découvrez les avantages du Data-Centric AI, un nouveau paradigme axé sur l'amélioration de la qualité des données, appliqué à la vision par ordinateur.