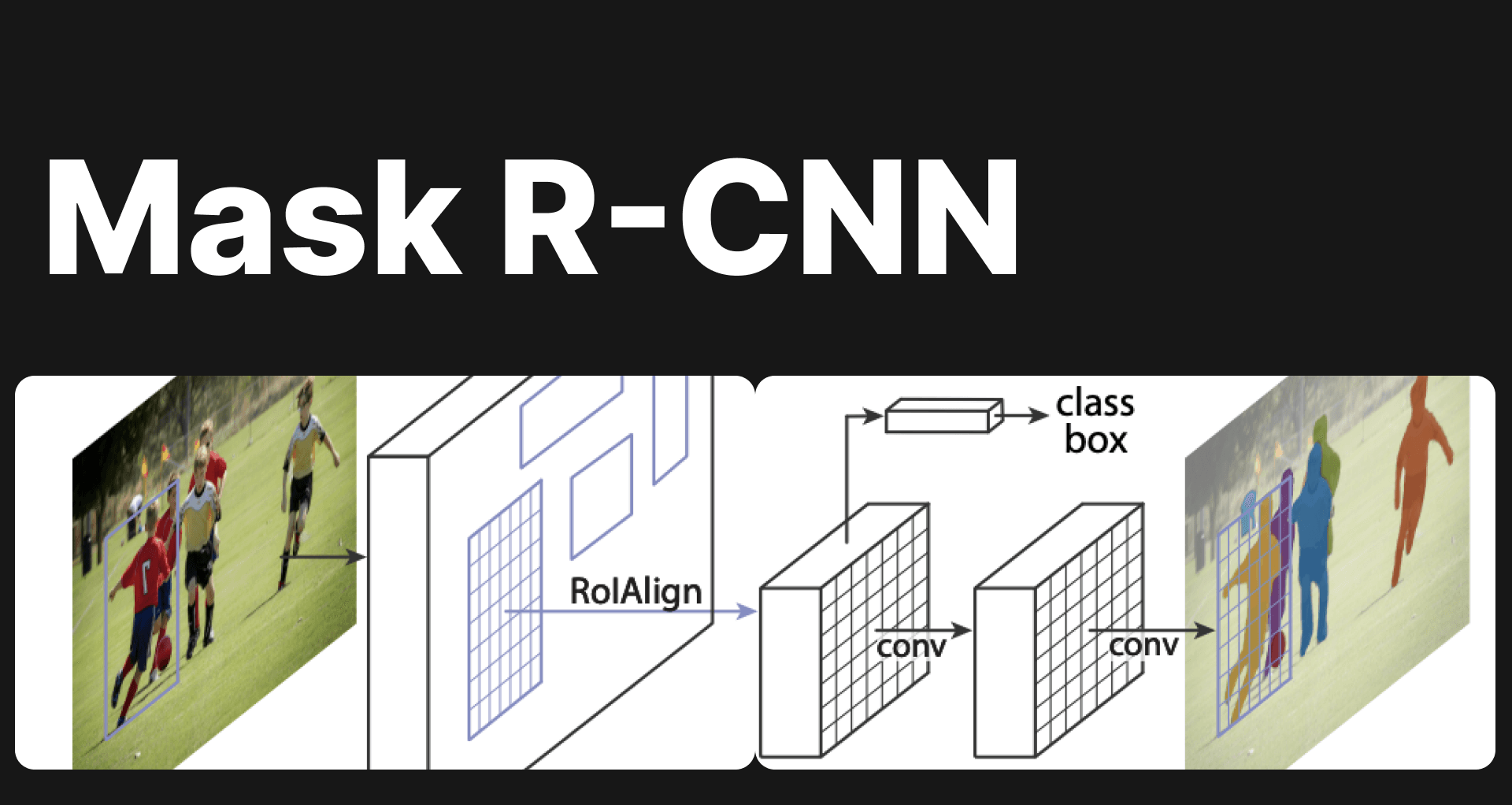
Mask R-CNN - Tout expliqué
Explorez Mask R-CNN : un outil révolutionnaire en vision par ordinateur pour la détection d'objets et la segmentation d'instances. Plongez dans son architecture et ses applications.
Picsellia Team
·8 min read
Livrez vos modeles plus vite
Suivez vos experiences, comparez les executions et iterez plus rapidement avec des outils integres.
En vision par ordinateur, différentes tâches existent comme présenté dans notre article précédent Segmentation vs Detection vs Classification in Computer Vision: A Comparative Analysis. Comme expliqué dans l'article, il existe deux types de segmentation, la segmentation sémantique et la segmentation d'instances. Dans cet article, nous allons découvrir l'une des architectures les plus puissantes pour la segmentation d'instances, à savoir Mask R-CNN.
Comprendre la segmentation d'instances
La segmentation d'instances va au-delà de la classification d'images et de la détection d'objets traditionnelles en fournissant une compréhension au niveau du pixel des objets dans une image.
La segmentation d'instances est en fait une combinaison de deux sous-problèmes : la détection d'objets et la segmentation sémantique. Elle vise à différencier les instances individuelles d'objets et à délimiter leurs contours avec précision. La boîte englobante est créée à partir de la détection d'images et les masques ombrés sont le résultat de la segmentation sémantique.
Ce niveau de granularité ouvre un large éventail d'applications, du comptage et suivi d'objets à la compréhension des formes et interactions des objets.
 Mask r cnn everything explained
Exemple de segmentation d'instances : https://blog.paperspace.com/
Mask r cnn everything explained
Exemple de segmentation d'instances : https://blog.paperspace.com/
Aperçu de l'histoire de Mask R-CNN
Introduit en 2014, R-CNN, Regions with Convolutional Neural Networks, était l'une des premières approches à utiliser les réseaux de neurones convolutifs pour la détection d'objets. R-CNN fonctionne en trois étapes :
- Génération de propositions de régions
- Extraction de caractéristiques de ces régions à l'aide de CNN pré-entraînés
- Classification des régions et ajustement des boîtes englobantes.
Cependant, en raison du traitement indépendant des régions proposées, R-CNN était lent mais tout de même prometteur.
Il a donné naissance un an plus tard à une version améliorée appelée Fast R-CNN, qui a significativement accéléré le processus de détection d'objets par rapport à R-CNN. En effet, au lieu de classifier indépendamment chaque région, il utilisait un seul réseau convolutif pour extraire les caractéristiques de l'image entière.
La même année, en 2015, Faster R-CNN est proposé, introduisant le concept du Region Proposal Network (RPN). Le RPN partage les caractéristiques CNN avec le détecteur d'objets pour générer automatiquement des régions d'intérêt (RoI) potentielles. Cette approche accélère davantage le processus de génération de propositions de régions et améliore les performances de détection d'objets.
En 2017, Mask R-CNN, qui étend le succès de Faster R-CNN à la segmentation d'instances, est présenté. Mask R-CNN incorpore un Mask Head dans l'architecture Faster R-CNN pour générer des masques de segmentation au niveau du pixel pour chaque objet détecté. Cette approche permet d'effectuer à la fois la détection d'objets et la segmentation d'instances dans un seul réseau. Mask R-CNN est largement reconnu pour ses performances exceptionnelles en détection d'objets et segmentation d'instances.
Depuis l'introduction de Mask R-CNN, de nombreuses améliorations et variantes ont été proposées pour améliorer sa vitesse et ses performances. Des architectures comme EfficientDet et Cascade Mask R-CNN ont également été développées pour repousser les limites de la détection d'objets et de la segmentation d'instances. Cependant, Mask R-CNN reste l'un des modèles les plus influents et les plus utilisés dans le domaine de la vision par ordinateur.
Processus étape par étape de Mask R-CNN pour la segmentation d'instances
 Mask r cnn everything explained
https://ars.els-cdn.com
Mask r cnn everything explained
https://ars.els-cdn.com
Plongeons dans le processus étape par étape de Mask R-CNN pour la segmentation d'instances.
Étape 1 : Réseau backbone
Le réseau backbone est la première étape de Mask R-CNN. Son rôle est de transformer l'image brute en une représentation riche de ses caractéristiques visuelles en extrayant les caractéristiques pertinentes de l'image d'entrée. Le backbone consiste typiquement en plusieurs couches convolutives, des opérations de pooling et d'autres opérations non linéaires qui permettent de capturer des informations de bas niveau à haut niveau dans l'image.
Étape 2 : Region Proposal Network (RPN)
Grâce aux caractéristiques extraites par le réseau backbone, le RPN scanne l'image et propose des régions d'objets potentielles en utilisant des boîtes d'ancrage prédéfinies. Ces boîtes d'ancrage ont différents rapports d'aspect et échelles et agissent comme des boîtes englobantes potentielles autour des objets.
Le RPN attribue un score à chaque proposition de région indiquant sa ressemblance avec un objet réel. Un score d'objectivité élevé implique une présence probable d'un objet d'intérêt dans la région proposée, tandis qu'un score faible suggère que la région est probablement du fond ou ne contient aucun objet pertinent.
 Mask r cnn everything explained
Premières propositions de régions, https://github.com/matterport/Mask_RCNN**
Mask r cnn everything explained
Premières propositions de régions, https://github.com/matterport/Mask_RCNN**
Étape 3 : Feature Pyramid Network (FPN)
Mask R-CNN incorpore un Feature Pyramid Network pour relever le défi de la représentation multi-échelle des caractéristiques. Le FPN construit une pyramide de caractéristiques en fusionnant les caractéristiques de différentes couches d'un réseau de neurones convolutif. Cette structure pyramidale fournit une représentation multi-échelle de l'image, avec des niveaux de caractéristiques à différentes résolutions spatiales.
Étape 4 : Region of Interest (RoI) Align
Une fois la pyramide de caractéristiques créée par le FPN, les propositions de régions générées par le RPN sont utilisées pour extraire les caractéristiques des régions d'intérêt. C'est là que le RoI Align entre en jeu. Au lieu d'utiliser l'opération traditionnelle de RoI Pooling, qui peut entraîner des problèmes d'alignement imprécis, Mask R-CNN utilise le RoI Align qui emploie l'interpolation bilinéaire pour échantillonner les caractéristiques de la carte de caractéristiques originale, résultant en un alignement précis des caractéristiques et une localisation exacte des contours des objets.
Train Mask R-CNN models without the MLOps headache
Picsellia handles dataset versioning, annotation, experiment tracking, and deployment — so you can focus on building better segmentation models.
Rejoignez des centaines d'ingenieurs CV qui livrent des modeles plus vite avec Picsellia
Étape 5 : Classification et régression de boîtes englobantes
Une fois les propositions de régions générées et alignées à l'aide du RoI Align, Mask R-CNN effectue la classification et la régression de boîtes englobantes. Il passe les caractéristiques alignées par RoI à travers un réseau entièrement connecté partagé, qui prédit les probabilités de classe pour chaque région proposée. Le réseau effectue également la régression des coordonnées des boîtes englobantes pour affiner leurs positions et tailles. Cette étape assure une classification précise des objets et une localisation exacte.
 Mask r cnn everything explained
https://github.com/matterport/Mask_RCNN
Mask r cnn everything explained
https://github.com/matterport/Mask_RCNN
Étape 6 : Mask Head et prédiction de masque
Le réseau Mask Head est responsable de la génération de masques au niveau du pixel pour chaque région d'objet détectée. Il prend les caractéristiques alignées par RoI en entrée et les passe à travers une série de couches convolutives et d'opérations de suréchantillonnage pour produire les masques de segmentation finaux. La branche de prédiction de masque, composée d'un classificateur de masque binaire, prédit si chaque pixel appartient au premier plan (objet) ou à l'arrière-plan. La sortie est un masque haute résolution pour chaque instance d'objet, délimitant avec précision les contours de l'objet.
 Mask r cnn everything explained
https://www.shuffleai.blog
Mask r cnn everything explained
https://www.shuffleai.blog
Étape 7 : Entraînement et inférence
Pour entraîner Mask R-CNN, un grand dataset annoté est nécessaire, avec des masques au niveau du pixel pour chaque instance d'objet. Pendant l'entraînement, le réseau est optimisé en utilisant une combinaison de fonctions de perte :
-
Perte de classification : Assure une classification précise des objets en comparant les probabilités de classe prédites avec les labels de vérité terrain.
-
Perte de régression de boîtes englobantes : Affine les coordonnées de boîtes englobantes prédites pour correspondre aux annotations de vérité terrain.
-
Perte de segmentation de masque : Compare les masques d'instances prédits avec les masques de vérité terrain pour guider le réseau dans la génération de résultats de segmentation précis.
Pendant l'inférence, Mask R-CNN applique le modèle entraîné à des images inédites, effectuant les propositions de régions, la classification, la régression de boîtes englobantes et la prédiction de masque de manière unifiée. Le résultat est une segmentation d'instances précise, avec des objets distinctement délimités et labellisés dans l'image.
 Mask r cnn everything explained
https://github.com/matterport/Mask_RCNN
Mask r cnn everything explained
https://github.com/matterport/Mask_RCNN
Performance et applications
La précision et la robustesse du modèle R-CNN en font un outil précieux dans une variété d'applications. La segmentation précise d'instances est essentielle dans des tâches telles que l'identification de piétons et d'objets sur les routes pour les voitures autonomes, la segmentation précise d'organes dans les images médicales, le suivi d'objets, la robotique et la réalité augmentée.
Cependant, obtenir une segmentation d'instances précise pose un certain nombre de problèmes. Les objets peuvent avoir des formes complexes, des occlusions ou des contours qui se chevauchent, rendant la séparation précise difficile. Les variations d'échelle, de conditions d'éclairage et d'orientation des objets ajoutent à la complexité. Les algorithmes de segmentation d'instances doivent être robustes et capables de gérer ces défis pour fournir des résultats fiables.
Conclusion
Mask R-CNN représente une avancée significative dans la réalisation d'une segmentation d'instances précise. En étendant le framework Faster R-CNN et en incorporant la segmentation au niveau du pixel, Mask R-CNN a établi de nouveaux standards dans les tâches de détection d'objets et de segmentation. Sa polyvalence, sa précision et sa robustesse en font un outil puissant pour les professionnels de la vision par ordinateur, des data scientists et ingénieurs machine learning aux CTO. Alors que la vision par ordinateur continue de progresser, nous pouvons nous attendre à de nouveaux raffinements et avancées dans les techniques de segmentation d'instances, repoussant les limites de ce que les machines peuvent accomplir dans la compréhension des données visuelles.
From annotation to deployment — one platform
Picsellia gives you pixel-level annotation tools, experiment tracking, and model deployment for instance segmentation projects. Used by 100+ CV teams.
Rejoignez des centaines d'ingenieurs CV qui livrent des modeles plus vite avec Picsellia
Suggestions Picsellia
Suivez chaque experience
Enregistrez automatiquement les metriques, parametres et artefacts. Comparez les executions cote a cote et livrez de meilleurs modeles plus vite.
Voir le suivi d'experiencesAutomatisez vos pipelines ML
Configurez l'entrainement et le deploiement continus avec des declencheurs automatiques, des deploiements shadow et des boucles de feedback.
Explorer les pipelines automatisesRestez informe
Recevez les derniers articles sur la vision par ordinateur, le MLOps et l'IA directement dans votre boite mail.
Articles associes
Fonctions d'activation et réseaux de neurones
Découvrez le rôle clé des fonctions d'activation dans les réseaux de neurones pour les tâches de vision par ordinateur. Apprenez-en plus sur Sigmoid, ReLU et d'autres pour un meilleur deep learning.

Comprendre le surapprentissage en machine learning
Apprenez a lutter contre le surapprentissage en machine learning avec des strategies efficaces et la plateforme MLOps de Picsellia. Evitez la memorisation du modele.

Comprendre le F1 Score en machine learning : la moyenne harmonique de la precision et du rappel
Dans cet article, nous allons approfondir le concept du F1 score, sa relation avec la precision et le rappel, et pourquoi il est avantageux d'utiliser le F1 score.