How To Ensure Data Quality – Best Practices
Data curation is the management of data in an organization such that it is readily available in the present and preserved for future use
Picsellia Team
·8 min read

Organize your visual data today
Version datasets, manage annotations, and track lineage from one place.
Artificial intelligence (AI) has seen substantial growth in the past decade. Today, AI models are better than ever and have replaced human labor in everyday tasks. However, scientists and engineers have recently started emphasizing the importance of data quality in building high-performance and robust AI models. AI pioneer Andrew NG states:
“Instead of focusing on the code, companies should focus on developing systematic engineering practices for improving data in ways that are reliable, efficient, and systematic. In other words, companies need to move from a model-centric approach to a data-centric approach.”
The data-centric notion of AI brings us to the importance of data curation. Data curation is the management of data in an organization such that it is readily available in the present and preserved for future use. Machine learning (ML) models benefit from organized data during training and re-training. Data curation techniques also involve analysis to extract useful features for ML training.
In computer vision (CV), image data is usually available with many data points since, in most cases, it is relatively easy to generate and synthesize. With massive image datasets, curation becomes an integral part of the CVOps pipeline. Let's discuss how data curation aids computer vision tasks.
Data Curation for Computer Vision
Computer vision engineers spend around 80% of their time curating data. These datasets must be constantly updated to keep up with modern business requirements. Companies must set up proper data management pipelines which allow the acquisition and annotation of data effectively.
A good dataset contains two main aspects, **quality **and diversity. Some of the well-known high-quality image datasets have millions of diverse images. Such as:
- MS-COCO (328,000 images)
- Image-Net (1.3 Mil images)
- Open-Images dataset (~10 Mil images)
Although these are used for benchmarking many state-of-the-art models, the datasets, in their raw form, contain many noisy samples and require a lot of preprocessing and cleaning before performing any tests. It shows how difficult it is to maintain a genuinely perfect dataset.
Creating valuable datasets is always a challenge. It is a recurring process that requires skills and patience. Let's look at some challenges while curating a dataset and understand why many public datasets are unsuitable for modern AI tools.
Challenges of Data Quality
If you search on Kaggle or other open data repositories, you will find a plethora of datasets. These datasets are free to use, but their open-source nature raises questions about their credibility. Many of these are uploaded by independent enthusiasts or researchers who put little effort into verifying their correctness and catering to missing values. If used for benchmarking by professionals, these will yield incorrect results, and the tested models will not be reliable.
Creating and maintaining a quality dataset brings a lot of challenges as it requires constant monitoring throughout its lifecycle. Let's discuss these challenges in detail below:
1. Ensuring Data Diversity
Data engineers are required to collect data from multiple sources under various conditions, ensuring diverse data collection. However, this is a tiresome and unexciting task, and proper data collection can take weeks to months. Many modern organizations even spend years collecting relevant data before utilizing it for practical applications.
 How to ensure data quality best practices 63287777fcaad2e4cbbcc493 data 20diversity
How to ensure data quality best practices 63287777fcaad2e4cbbcc493 data 20diversity
For computer vision applications, this means collecting images for a given subject. Say you want to create a dataset of bird photos. You will have to capture images of all kinds of birds. Each category (or bird species) will require pictures from multiple angles, in different lighting conditions, and at different elevations. These are just some of the variations. In reality, you will have to take care of many more scenarios.
2. Data Source Accuracy
Raw data is the foundation of all data science and machine learning practices, so any inaccuracy costs an organization significantly. When you collect data from various sources, ensuring accurate measurements becomes challenging. If inaccurate information passes on to further processing stages, it becomes even more difficult to trace the source of error.
3. Data Annotation
Once you have collected data, creating ground truths is the next necessary step. Labeling data is just as tedious as data collection since you have thousands or millions of images. Image datasets are labeled in different ways depending on the problem. A few examples are:
- Class Association for classification tasks.
- Bounding box/mask creation for object detection.
- Image descriptions for image captioning.
4. Data Security
Data security and privacy are always a top priority for organizations as hackers constantly look for opportunities for a break-in. Companies spend a lot of resources, money, and time on data collection and refining, and any kind of infringement results in huge losses.
5. Complex Storage Architecture
Data should be accessible to all relevant data engineers and non-data team members. Traditional SQL databases are more than enough for easy storage and access for structured or tabular data, but they cannot be used to store image data. Storing unstructured data requires NoSQL databases such as MongoDB or cloud storage like Amazon S3 bucket. Moreover, a centralized data repository like a data warehouse or data lake can be a more flexible option.
These shortcomings are a significant reason many data-intensive ML projects fail. Without following the correct practices, organizations end up wasting a lot of time fixing errors and mistakes.
*But what are the proper practices for curating data? *
Let's discuss them below.
Best Practices for Image Data Curation
Building a suitable dataset can be overwhelming, but it does not have to be. With proper planning and guidance, engineers can get the most out of the data and minimize their workload. Let us dig deeper into what it takes to create a healthy dataset.
1. Understand Your Problem
Data collection is brutal and even more so if you take the wrong direction. Without understanding the problem, you may waste time gathering images useless to your ML model. It is always helpful to take a step back and reiterate your requirements to know what you need.
Most computer vision tasks require clear images with the subject in complete view. Using such images, CV engineers can increase the size of the dataset by creating variations via augmentation techniques.
Knowing what you need saves time and effort and prevents inaccuracies from plaguing the dataset.
2. Data Annotation Guides
Assigning data labeling tasks to inexperienced and non-technical resources is a regular practice in the industry to reduce annotation costs. Although it takes the load off the data engineers, it raises questions about the quality of data annotation.
 How to ensure data quality best practices 632877951ded79ab120a978a data 20annotation 20guide
How to ensure data quality best practices 632877951ded79ab120a978a data 20annotation 20guide
Machine learning models use ground truth labels to train themselves. Any error within these labels results in a loss of model performance, so annotators must take extra care to ensure all data is labeled appropriately. Annotation guides can help resources understand how to label data according to the given class.
3. Embeddings and Self-Supervised Data Annotation
Self-supervised data annotation is a relatively new concept, but organizations have already started using it to speed up data labeling. Various open-source computer vision models are available online, specializing in image classification or object detection. Self-supervised data annotation uses these models to generate labels and sort images into categories. Annotators can manually verify these images to remove any inconsistencies, a much quicker process with a shallow margin of error.
 How to ensure data quality best practices 632877a27f32ef6bc5985fa1 self supervised 201
How to ensure data quality best practices 632877a27f32ef6bc5985fa1 self supervised 201
Furthermore, embeddings or feature maps can be generated from images using convolutional neural networks (CNNs). Using clustering algorithms, computer vision engineers can use these embeddings to group similar images.
4. Eliminating Data Silos
Data silos occur when the organization's departments (like sales, marketing, and operations) only manage its data. Enterprise organizations cannot afford these data silos because it hinders the organization from observing a 360° view of their customers or business data, resulting in incomplete analytics and inefficient business decision-making. Moreover, data silos minimize cross-team collaboration, which is counterproductive for modern organizations.
To eliminate these data silos, businesses can set up a centralized storage pipeline like a data warehouse or data lake to curate data from disparate sources. Hence, eliminating any data silos and promoting data democratization across the organization.
Ensure Data Quality with Picsellia
Picsellia offers a wide variety of tools that automate the data curation process. Our end-to-end data management solution allows for easy storage and access to data.
Picsellia's CVOps platform offers version control features for datasets, so you would never have to worry about losing relevant data. Other than data storage, Picsellia's AI-assisted labeling tools enhance the speed and accuracy of annotations by offering a pre-annotation feature to automate labeling.
Moreover, our experiment tracking feature allows you to keep track of the multiple experiments executed on your various datasets. You can use these track records to fine-tune your dataset and bring the best out of your model.
To experience our exceptional data management solutions, book your demo today.
Related from Picsellia
Organize and version your datasets
Version, slice, and manage datasets with full traceability — from raw images to production-ready splits.
Explore Dataset ManagementAnnotate faster with AI assistance
Picsellia's labeling tool supports bounding boxes, polygons, and segmentation masks with built-in AI assistance to speed up annotation.
Explore the Labeling ToolStay up to date
Get the latest posts on computer vision, MLOps, and AI delivered to your inbox.
Related articles

Computer Vision Dataset Slicing
Discover dataset slicing, a technique used to divide large datasets into smaller parts to train and test models and improve model accuracy.
Best object detection datasets in 2024
Looking to train your object detection models? Discover a wide variety of high-quality object detection datasets to fuel your AI projects.
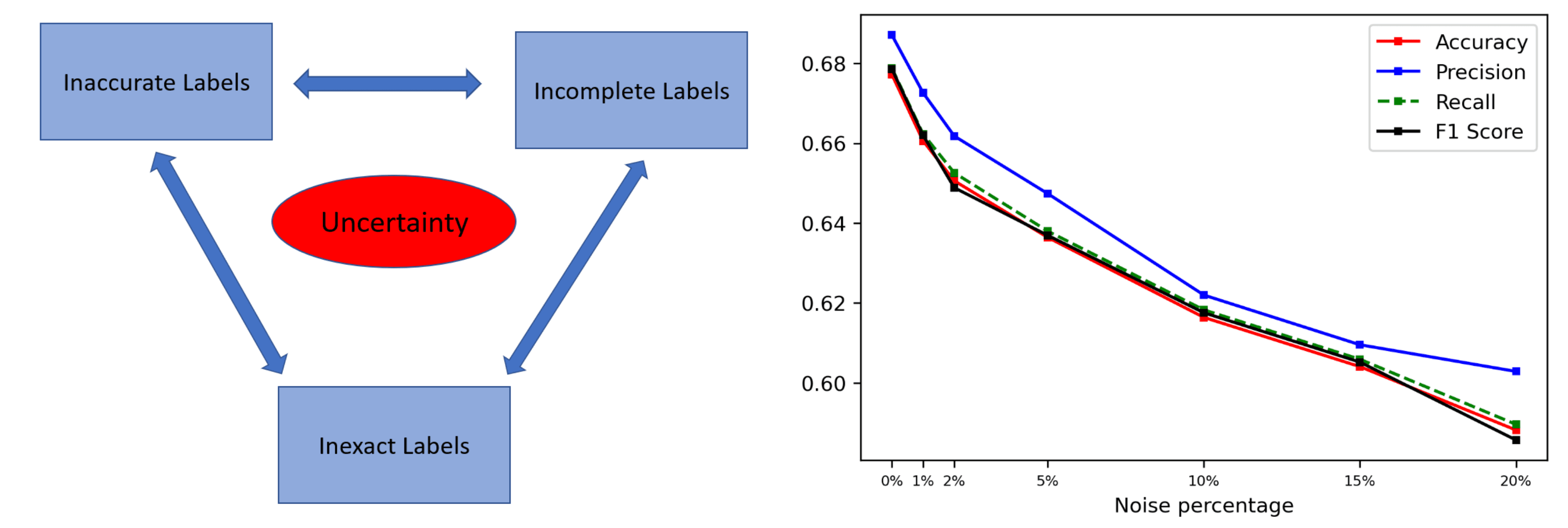
Data-Centric AI: A Guide to Improving ML Performance Through Data
Learn how the benefits of Data-Centric AI, a new paradigm focusing on improving data quality applies to computer vision.